Kinetics IV
Contents
Kinetics IV#
Today, we’ll discuss analysis of kinetic data obtained in a CSTR. We’ll consider the impacts of measurement error and how it can be managed, and we’ll also discuss how to work with a maddening set of data that were not obtained very systematically…
import numpy as np
import matplotlib.pyplot as plt
import scipy.optimize as opt
import scipy.stats as stats
from math import ceil
Example Problem 01#
Analysis of Data obtained in a CSTR
The following reaction is carried out in a 0.275L CSTR at steady state. The experiment is performed by varying the inlet volumetric flowrate (Q\(_f\)) of a solution that always has a concentration \(C_{A_f}\) = 10 mol L\(^{-1}\). You may assume the fluid density is constant so that \(Q = Q_f\).
You measure the concentration of species A and species B in the effluent stream from the reactor. The data are compiled in the table below. For now, we’ll look at essentially perfect data just to get a feel for the way that we handle the analysis without also dealing with precision and measurement uncertainty.
Q\(_f\) (L/sec) |
C\(_A\) (mol/L) |
C\(_B\) (mol/L) |
|---|---|---|
2.750 |
9.98 |
2.29 x 10\(^{-2}\) |
5.500 x 10\(^{-1}\) |
9.89 |
1.14 x 10\(^{-1}\) |
3.667 x 10\(^{-1}\) |
9.83 |
1.70 x 10\(^{-1}\) |
2.750 x 10\(^{-1}\) |
9.78 |
2.25 x 10\(^{-1}\) |
1.375 x 10\(^{-1}\) |
9.56 |
4.40 x 10\(^{-1}\) |
5.500 x 10\(^{-2}\) |
8.97 |
1.03 |
2.750 x 10\(^{-2}\) |
8.13 |
1.87 |
1.833 x 10\(^{-2}\) |
7.43 |
2.57 |
1.375 x 10\(^{-2}\) |
6.85 |
3.15 |
5.500 x 10\(^{-3}\) |
4.65 |
5.35 |
2.750 x 10\(^{-3}\) |
3.03 |
6.97 |
Assuming the reaction rate is described by power law kinetics,
where \(\alpha\) is an integer, use the measured concentrations of A in the reactor effluent to determine the reaction order in A and the rate constant for this reaction.
Solution to Example Problem 01#
Let’s stick with our conventional wisdom that, if we want to determine the reaction order with respect to A, we need to know how the rate of reaction changes in response to the concentration of species A. This is easiest to do if everything else is constant. Fortunately, these reactions are performed at constant temperature and in a solvent, so the fluid density is constant. Also, we know from the problem statement that the rate of reaction does not depend on B. This allows us to focus on how changing the concentration of A will impact the rate of reaction.
Estimation of reaction rates in a CSTR at Steady State#
As with a batch reactor, the starting point for this analysis is a material balance. We’ll choose to work with a balance on A. The problem statement requests information about the order in A, so this is a sensible approach.
For a CSTR at steady state:
We are given data about concentrations and volumetric flowrates, so I’ll recast this balance in terms of those parameters:
Dividing through by the feed volumetric flowrate, we get:
Finally, recognizing that we have a single reaction here, we can make the substitution that \(R_A = -r\):
And we can solve that balance for r to get:
Interesting – in a CSTR, dividing \(\Delta C_A\) by \(\Delta \tau\) gives us a direct calculation of reaction rate at the concentration inside of the CSTR (rather than a finite difference approximation like in a batch reactor). That seems promising…
Once we have a reaction rate calculated, it reflects the conditions inside the CSTR, which is a well-mixed reactor. That means that solving this equation for each experimental condition will give us a set of reaction rates measured at various concentrations of A.
Analysis of Perfect Data#
First, we’ll analyze the data set that I generated by solving the material balance for known kinetics.
V = 0.275 #L
CAf = 10 #mol/L
Qftrue = np.array([2.7500000000, 0.5500000000, 0.3666666667, 0.2750000000, 0.1375000000, 0.0550000000, 0.0275000000, 0.0183333333, 0.0137500000, 0.0055000000, 0.0027500000]) #L/sec
CAtrue = np.array([9.9770527786, 9.8863074642, 9.8304251659, 9.7751710655, 9.5602294455, 8.9686098655, 8.1300813008, 7.4349442379, 6.8493150685, 4.6511627907, 3.0303030303]) #mol/L
tautrue = V/Qftrue
rtrue = (CAf - CAtrue)/tautrue
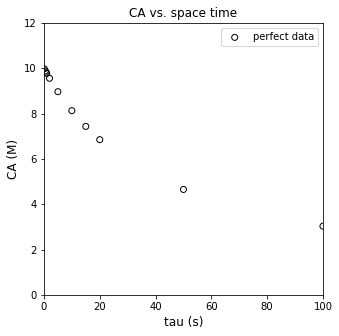
plt.figure(1, figsize = (5, 5))
plt.scatter(tautrue, CAtrue, marker = 'o', color = 'none', edgecolor = 'black', label = 'perfect data')
plt.xlabel('tau (s)', fontsize = 12)
plt.ylabel('CA (M)', fontsize = 12)
plt.title('CA vs. space time')
plt.xlim(0, 100)
plt.ylim(0, 12)
plt.legend()
plt.show()
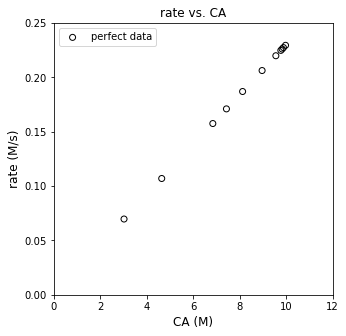
plt.figure(2, figsize = (5, 5))
plt.scatter(CAtrue, rtrue, marker = 'o', color = 'none', edgecolor = 'black', label = 'perfect data')
plt.xlabel('CA (M)', fontsize = 12)
plt.ylabel('rate (M/s)', fontsize = 12)
plt.title('rate vs. CA')
plt.xlim(0, 12)
plt.ylim(0, 0.25)
plt.legend()
plt.show()
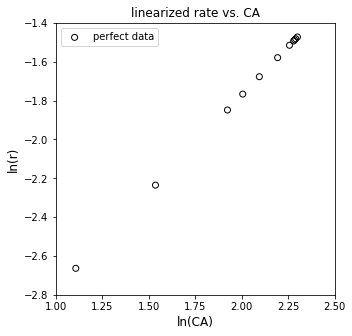
plt.figure(3, figsize = (5, 5))
plt.scatter(np.log(CAtrue), np.log(rtrue), marker = 'o', color = 'none', edgecolor = 'black', label = 'perfect data')
plt.xlabel('ln(CA)', fontsize = 12)
plt.ylabel('ln(r)', fontsize = 12)
plt.title('linearized rate vs. CA')
plt.xlim(1.0, 2.5)
plt.xticks(np.arange(1.0, 2.51, 0.25))
plt.ylim(-2.8, -1.4)
plt.legend()
plt.show()
Assessing linearity in rate data#
Well, that looks linear, suggesting we have power law kinetics, though the reaction order is unknown currently. We can estimate the reaction order and the rate constant by linear regression, which I implemented below using standard matrix notation that would be in your statistics textbook from CEN 212. As a refresher, we’re solving this problem:
Where X is the truncated Vandermonde matrix up to whatever order we’re considering (here, it is up to first order). A is the matrix of polynomial coefficients. Here it is of length 2 because we are fitting a first order equation to the data, so, the slope of the line is given by A[0], and the y-intercept is given by A[1]. Y is a vector of our measurements.
In our linearized model, our “X” values are given by ln(CA), and our Y values are given by ln(r).
The X matrix is “tall” here. It has 6 rows (because we made six measurements), but only 2 columns (because we only have a first order model with two coefficients). The Y vector is a 6x1 column. This system is overdetermined, and there is no single line that will pass through all data points. There is however a unique least squares solution that gives the line that models all data points with minimum residual error. That is given by:
Which, in numpy would be solved either as:
A = np.linalg.solve(X.T@X, X.T@Y)
Or the convenience least squares solution in numpy:
A = np.linalg.lstsq(X, Y)
I use the first one because I just do all the linear regression calculations and definitions manually. We calculate the residual sum of squares as usual:
Which, for a linear regression problem is equivalent to:
In numpy that would be:
SSE = (Y - X@A).T@(Y - X@A)
The total sum of squares quantifies the error between the measurement and the mean of measurments:
If we have the residual and total sum of squares, we can calculate the coefficient of determination:
If you want to obtain estimates of standard error in the slope and y intercept that you regress, you need to estimate the covariance matrix. First, we estimate the variance, \(\sigma^2\) with the following:
and:
Where \(n_m\) is the number of measurements and \(n_p\) is the number of regressed parameters. This is also known as the “degrees of freedom” in our regression.
With that, we can estimate the covariance matrix from the measured data:
The standard error in our regressed parameters is given by the diagonal elements in the following matrix:
From that, we get the standard error in the slope from se[0,0] and the standard error in the intercept from se[1,1], i.e., the diagonal elements.
If you want to calculate confidence intervals, they are given by:
Finally, noting that I’m working with a linear system, if I want to generate predicted values of my measured quantity (here ln(CA)), I can do so by multiplying my truncated vandermonde matrix by the regressed coefficients:
##These are textbook linear least squares formulas that I got from my statistics book
##They are calculating statistics on the fit, standard errors, confidence intervals, SSE, SST, R2, etc.
X = np.vander(np.log(CAtrue),2) #X matrix, powers of measured ln(CA)
Y = np.log(rtrue) #Y vector, values of measured ln(r)
A = np.linalg.solve(X.T@X, X.T@Y) #regression coefficients, slope and intercept
SSE = (Y - X@A).T@(Y-X@A) #Residual sum of squares, equivalent to sum (y_i - y_hat_i)^2
SST = sum((Y - np.mean(Y))**2) #Total sum of squares, SST = sum(y_i - mean(y))^2
R2 = 1 - SSE/SST #R2
s2 = SSE/(len(Y) - len(A)) #essentially, a standard deviation approximation for variance, sigma^2
cov = s2*np.linalg.inv((X.T@X)) #covariance matrix
se = np.sqrt(abs(cov)) #standard error matrix; diagonal elements are standard error in each coefficient
ci = stats.t.ppf(0.975, len(Y) - len(A))*se #confidence intervals
Ypred = X@A #predicted values of Y
print(A)
print(f'The R2 value for this fit is {R2:3.3f}')
print(f'The regressed order is {A[0]:3.3f} plus/minus {ci[0,0]:3.4f} and the regressed value of ln(k) is {A[1]:3.3f} plus/minus {ci[1,1]:3.3f}')
print(f'The rate constant is approximately {np.exp(A[1]):3.3f} s^-1')
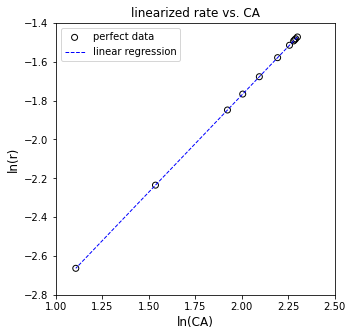
plt.figure(3, figsize = (5, 5))
plt.scatter(np.log(CAtrue), np.log(rtrue), marker = 'o', color = 'none', edgecolor = 'black', label = 'perfect data')
plt.plot(np.log(CAtrue), Ypred, color = 'blue', linestyle = 'dashed', linewidth = 1, label = 'linear regression')
plt.xlabel('ln(CA)', fontsize = 12)
plt.ylabel('ln(r)', fontsize = 12)
plt.title('linearized rate vs. CA')
plt.xlim(1.0, 2.5)
plt.xticks(np.arange(1.0, 2.51, 0.25))
plt.ylim(-2.8, -1.4)
plt.legend()
plt.show()
[ 1. -3.77226106]
The R2 value for this fit is 1.000
The regressed order is 1.000 plus/minus 0.0000 and the regressed value of ln(k) is -3.772 plus/minus 0.000
The rate constant is approximately 0.023 s^-1
Analysis of more realistic data…#
Now let’s work toward what a real data set might look like. First, we’d never keep 10 sig figs for data we generated from, e.g., gas-chromatography in the lab. Let’s round the data to expected experimental precision; this includes measurements obtained at very short residence times by increasing the inlet flowrate to very large values. At this point, we are still looking at “perfect” data that I generated by solving a CSTR model. I’ve just truncated the results and reported only 3 significant figures everywhere.
V = 0.275 #L
CAf = 10 #mol/L
Qfdata = np.array([2.75, 0.55, 0.3667, 0.275, 0.1375, 0.055, 0.0275, 0.01833, 0.01375, 0.0055, 0.00275]) #mol/L
CAdata = np.array([9.98, 9.89, 9.83, 9.78, 9.56, 8.97, 8.13, 7.43, 6.85, 4.65, 3.03]) #L/sec
taudata = V/Qfdata
rdata = (CAf - CAdata)/taudata
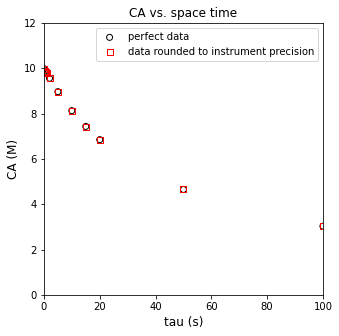
plt.figure(1, figsize = (5, 5))
plt.scatter(tautrue, CAtrue, marker = 'o', color = 'none', edgecolor = 'black', label = 'perfect data')
plt.scatter(taudata, CAdata, marker = 's', color = 'none', edgecolor = 'red', label = 'data rounded to instrument precision')
plt.xlabel('tau (s)', fontsize = 12)
plt.ylabel('CA (M)', fontsize = 12)
plt.xlim(0, 100)
plt.ylim(0, 12)
plt.title('CA vs. space time')
plt.legend()
plt.show()
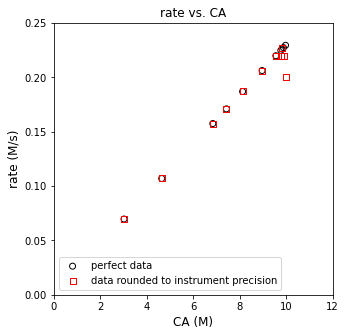
plt.figure(2, figsize = (5, 5))
plt.scatter(CAtrue, rtrue, marker = 'o', color = 'none', edgecolor = 'black', label = 'perfect data')
plt.scatter(CAdata, rdata, marker = 's', color = 'none', edgecolor = 'red', label = 'data rounded to instrument precision')
plt.xlabel('CA (M)', fontsize = 12)
plt.ylabel('rate (M/s)', fontsize = 12)
plt.title('rate vs. CA')
plt.xlim(0, 12)
plt.ylim(0, 0.25)
plt.legend()
plt.show()
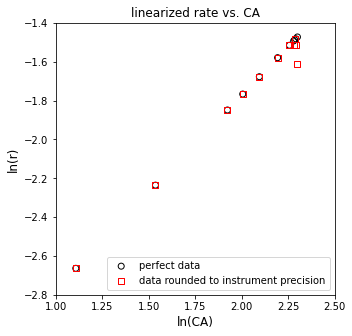
plt.figure(3, figsize = (5, 5))
plt.scatter(np.log(CAtrue), np.log(rtrue), marker = 'o', color = 'none', edgecolor = 'black', label = 'perfect data')
plt.scatter(np.log(CAdata), np.log(rdata), marker = 's', color = 'none', edgecolor = 'red', label = 'data rounded to instrument precision')
plt.xlabel('ln(CA)', fontsize = 12)
plt.ylabel('ln(r)', fontsize = 12)
plt.title('linearized rate vs. CA')
plt.xlim(1.0, 2.5)
plt.xticks(np.arange(1.0, 2.51, 0.25))
plt.ylim(-2.8, -1.4)
plt.legend()
plt.show()
display(np.round(np.vstack((CAtrue, CAdata, (CAtrue - CAdata)*100/CAtrue)).T, 3))
display(np.round(np.vstack((rtrue, rdata, (rtrue - rdata)*100/rtrue)).T, 3))
array([[ 9.977e+00, 9.980e+00, -3.000e-02],
[ 9.886e+00, 9.890e+00, -3.700e-02],
[ 9.830e+00, 9.830e+00, 4.000e-03],
[ 9.775e+00, 9.780e+00, -4.900e-02],
[ 9.560e+00, 9.560e+00, 2.000e-03],
[ 8.969e+00, 8.970e+00, -1.500e-02],
[ 8.130e+00, 8.130e+00, 1.000e-03],
[ 7.435e+00, 7.430e+00, 6.600e-02],
[ 6.849e+00, 6.850e+00, -1.000e-02],
[ 4.651e+00, 4.650e+00, 2.500e-02],
[ 3.030e+00, 3.030e+00, 1.000e-02]])
array([[ 2.2900e-01, 2.0000e-01, 1.2843e+01],
[ 2.2700e-01, 2.2000e-01, 3.2480e+00],
[ 2.2600e-01, 2.2700e-01, -2.6000e-01],
[ 2.2500e-01, 2.2000e-01, 2.1480e+00],
[ 2.2000e-01, 2.2000e-01, -5.2000e-02],
[ 2.0600e-01, 2.0600e-01, 1.3500e-01],
[ 1.8700e-01, 1.8700e-01, -4.0000e-03],
[ 1.7100e-01, 1.7100e-01, -1.7500e-01],
[ 1.5800e-01, 1.5800e-01, 2.2000e-02],
[ 1.0700e-01, 1.0700e-01, -2.2000e-02],
[ 7.0000e-02, 7.0000e-02, -4.0000e-03]])
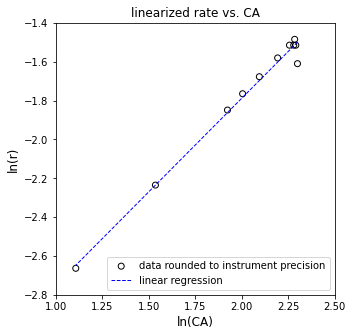
Linear Regression on Data Rounded to Instrument Precision#
Just with rounding error, we can see some issues already starting to pop up here. Data look mostly linear, except for at very high concentrations of A. Let’s run through the regression and see what we get back.
##These are textbook linear least squares formulas that I got from my statistics book
##They are calculating statistics on the fit, standard errors, confidence intervals, SSE, SST, R2, etc.
X = np.vander(np.log(CAdata),2) #X matrix, powers of measured ln(CA)
Y = np.log(rdata) #Y vector, values of measured ln(r)
A = np.linalg.solve(X.T@X, X.T@Y) #regression coefficients, slope and intercept
SSE = (Y - X@A).T@(Y-X@A) #Residual sum of squares, equivalent to sum (y_i - y_hat_i)^2
SST = sum((Y - np.mean(Y))**2) #Total sum of squares, SST = sum(y_i - mean(y))^2
R2 = 1 - SSE/SST #R2
s2 = SSE/(len(Y) - len(A)) #essentially, a standard deviation approximation for variance, sigma^2
cov = s2*np.linalg.inv((X.T@X)) #covariance matrix
se = np.sqrt(abs(cov)) #standard error matrix; diagonal elements are standard error in each coefficient
ci = stats.t.ppf(0.975, len(Y) - len(A))*se #confidence intervals
Ypred = X@A #predicted values of Y
print(A)
print(f'The R2 value for this fit is {R2:3.3f}')
print(f'The regressed order is {A[0]:3.3f} plus/minus {ci[0,0]:3.4f} and the regressed value of ln(k) is {A[1]:3.3f} plus/minus {ci[1,1]:3.3f}')
print(f'The rate constant is approximately {np.exp(A[1]):3.3f} s^-1')
plt.figure(3, figsize = (5, 5))
plt.scatter(np.log(CAdata), np.log(rdata), marker = 'o', color = 'none', edgecolor = 'black', label = 'data rounded to instrument precision')
plt.plot(np.log(CAdata), Ypred, color = 'blue', linestyle = 'dashed', linewidth = 1, label = 'linear regression')
plt.xlabel('ln(CA)', fontsize = 12)
plt.ylabel('ln(r)', fontsize = 12)
plt.title('linearized rate vs. CA')
plt.xlim(1.0, 2.5)
plt.xticks(np.arange(1.0, 2.51, 0.25))
plt.ylim(-2.8, -1.4)
plt.legend()
plt.show()
[ 0.96411599 -3.71675384]
The R2 value for this fit is 0.989
The regressed order is 0.964 plus/minus 0.0777 and the regressed value of ln(k) is -3.717 plus/minus 0.160
The rate constant is approximately 0.024 s^-1
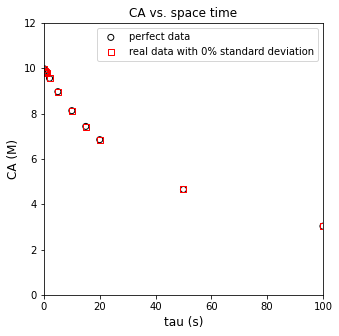
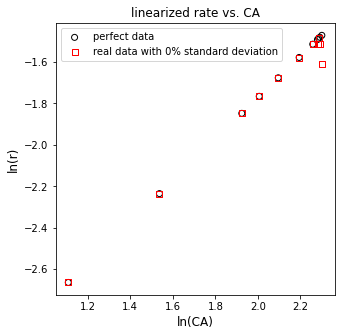
Adding Noise to the Data (simulating a real experiment)#
Now we are going to make this data resemble something we’d get in a lab by adding some random noise. This is gaussian noise (I’m adding a random number taken from a gaussian distribution with a given standard deviation). For now, we’ll look at how that impacts our measurments and the rates that we estimate from those measurements.
noise_level = 0 #percent standard deviation on the mean.
np.random.seed(ceil(noise_level))
V = 0.275 #L
CAf = 10 #mol/L
Qfdata = np.array([2.75, 0.55, 0.3667, 0.275, 0.1375, 0.055, 0.0275, 0.01833, 0.01375, 0.0055, 0.00275]) #mol/L
CAdata = np.array([9.98, 9.89, 9.83, 9.78, 9.56, 8.97, 8.13, 7.43, 6.85, 4.65, 3.03]) #L/sec
taudata = V/Qfdata
noise = CAdata*np.random.normal(0, noise_level/100, CAdata.shape)
CAdatan = CAdata + noise
rdata = (CAf - CAdata)/taudata
rdatan = (CAf - CAdatan)/taudata
plt.figure(1, figsize = (5, 5))
plt.scatter(tautrue, CAtrue, marker = 'o', color = 'none', edgecolor = 'black', label = 'perfect data')
plt.scatter(taudata, CAdatan, marker = 's', color = 'none', edgecolor = 'red', label = f'real data with {noise_level}% standard deviation')
plt.xlabel('tau (s)', fontsize = 12)
plt.ylabel('CA (M)', fontsize = 12)
plt.xlim(0, 100)
plt.ylim(0, 12)
plt.title('CA vs. space time')
plt.legend()
plt.show()
plt.figure(2, figsize = (5, 5))
plt.scatter(CAtrue, rtrue, marker = 'o', color = 'none', edgecolor = 'black', label = 'perfect data')
plt.scatter(CAdatan, rdatan, marker = 's', color = 'none', edgecolor = 'red', label = f'real data with {noise_level}% standard deviation')
plt.xlabel('CA (M)', fontsize = 12)
plt.ylabel('rate (M/s)', fontsize = 12)
plt.title('rate vs. CA')
#plt.xlim(0, 12)
#plt.ylim(0, 0.4)
plt.legend()
plt.show()
plt.figure(3, figsize = (5, 5))
plt.scatter(np.log(CAtrue), np.log(rtrue), marker = 'o', color = 'none', edgecolor = 'black', label = 'perfect data')
plt.scatter(np.log(CAdatan), np.log(rdatan), marker = 's', color = 'none', edgecolor = 'red', label = f'real data with {noise_level}% standard deviation')
plt.xlabel('ln(CA)', fontsize = 12)
plt.ylabel('ln(r)', fontsize = 12)
plt.title('linearized rate vs. CA')
#plt.xlim(1.0, 2.5)
#plt.xticks(np.arange(1.0, 2.51, 0.25))
#plt.ylim(-1.0, -3.0)
plt.legend()
plt.show()
display(np.vstack((CAtrue, CAdatan, (CAtrue - CAdatan)*100/CAtrue)).T)
display(np.round(np.vstack((rtrue, rdatan, (rtrue - rdatan)*100/rtrue)).T, 3))

array([[ 9.97705278e+00, 9.98000000e+00, -2.95400001e-02],
[ 9.88630746e+00, 9.89000000e+00, -3.73499996e-02],
[ 9.83042517e+00, 9.83000000e+00, 4.32500012e-03],
[ 9.77517107e+00, 9.78000000e+00, -4.93999999e-02],
[ 9.56022945e+00, 9.56000000e+00, 2.39999993e-03],
[ 8.96860987e+00, 8.97000000e+00, -1.54999997e-02],
[ 8.13008130e+00, 8.13000000e+00, 9.99999840e-04],
[ 7.43494424e+00, 7.43000000e+00, 6.64999998e-02],
[ 6.84931507e+00, 6.85000000e+00, -9.99999990e-03],
[ 4.65116279e+00, 4.65000000e+00, 2.50000000e-02],
[ 3.03030303e+00, 3.03000000e+00, 9.99999990e-03]])
array([[ 2.2900e-01, 2.0000e-01, 1.2843e+01],
[ 2.2700e-01, 2.2000e-01, 3.2480e+00],
[ 2.2600e-01, 2.2700e-01, -2.6000e-01],
[ 2.2500e-01, 2.2000e-01, 2.1480e+00],
[ 2.2000e-01, 2.2000e-01, -5.2000e-02],
[ 2.0600e-01, 2.0600e-01, 1.3500e-01],
[ 1.8700e-01, 1.8700e-01, -4.0000e-03],
[ 1.7100e-01, 1.7100e-01, -1.7500e-01],
[ 1.5800e-01, 1.5800e-01, 2.2000e-02],
[ 1.0700e-01, 1.0700e-01, -2.2000e-02],
[ 7.0000e-02, 7.0000e-02, -4.0000e-03]])
##These are textbook linear least squares formulas that I got from my statistics book
##They are calculating statistics on the fit, standard errors, confidence intervals, SSE, SST, R2, etc.
X = np.vander(np.log(CAdatan),2) #X matrix, powers of measured ln(CA)
Y = np.log(rdatan) #Y vector, values of measured ln(r)
A = np.linalg.solve(X.T@X, X.T@Y) #regression coefficients, slope and intercept
SSE = (Y - X@A).T@(Y-X@A) #Residual sum of squares, equivalent to sum (y_i - y_hat_i)^2
SST = sum((Y - np.mean(Y))**2) #Total sum of squares, SST = sum(y_i - mean(y))^2
R2 = 1 - SSE/SST #R2
s2 = SSE/(len(Y) - len(A)) #essentially, a standard deviation approximation for variance, sigma^2
cov = s2*np.linalg.inv((X.T@X)) #covariance matrix
se = np.sqrt(abs(cov)) #standard error matrix; diagonal elements are standard error in each coefficient
ci = stats.t.ppf(0.975, len(Y) - len(A))*se #confidence intervals
Ypred = X@A #predicted values of Y
print(A)
print(f'The R2 value for this fit is {R2:3.3f}')
print(f'The regressed order is {A[0]:3.3f} plus/minus {ci[0,0]:3.4f} and the regressed value of ln(k) is {A[1]:3.3f} plus/minus {ci[1,1]:3.3f}')
print(f'The rate constant is approximately {np.exp(A[1]):3.3f} s^-1')
plt.figure(3, figsize = (5, 5))
plt.scatter(np.log(CAdatan), np.log(rdatan), marker = 'o', color = 'none', edgecolor = 'black', label = f'real data with {noise_level}% standard deviation')
plt.plot(np.log(CAdatan), Ypred, color = 'blue', linestyle = 'dashed', linewidth = 1, label = 'linear regression')
plt.xlabel('ln(CA)', fontsize = 12)
plt.ylabel('ln(r)', fontsize = 12)
plt.title('linearized rate vs. CA')
#plt.xlim(1.0, 2.5)
#plt.xticks(np.arange(1.0, 2.51, 0.25))
#plt.ylim(-1.4, -2.8)
plt.legend()
plt.show()
[ 0.96411599 -3.71675384]
The R2 value for this fit is 0.989
The regressed order is 0.964 plus/minus 0.0777 and the regressed value of ln(k) is -3.717 plus/minus 0.160
The rate constant is approximately 0.024 s^-1
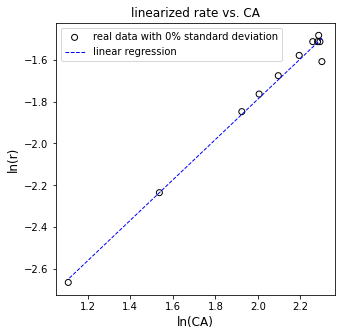
The problem above isn’t in our logic or in our math…it’s in our precision, specifically the ability to measure concentrations in the laboratory. Consider our definition of the rate in this CSTR as we’ve defined it so far. It is based on measuring the change in the concentration of species A relative to the feed at a given residence time:
If we go to residence times near zero, then our fractional conversion goes to zero (consider that \(X_A = r\tau/C_{Af}\)). In the limit of zero conversion, then:
Measuring precise changes in the concentration of reactant as the conversion of that reactant approaches zero is very difficult. It only takes a bit of uncertainty in our measurements before we’re getting results like \(C_A > C_{Af}\) for very small values of \(\tau\). Physically, that’s impossible for this reaction, but our limits on precision make it something we have to contend with. When we’re in this situation of trying to determine reaction rates at nearly zero conversion, the better approach is to do this based on a balance on our product:
Since \(R_B = r\), this can be solved to give:
Now, we’re basically measuring the change in concentration of species B relative to zero (the inlet concentration of B). Those measurements are still subject to the usual uncertainty, but we’ll see that the reaction rates we estimate are far more precise in the limit of zero conversion.
noise_level = 0 #percent standard deviation on the mean.
np.random.seed(ceil(noise_level))
V = 0.275 #L
CAf = 10 #mol/L
Qfdata = np.array([2.75, 0.55, 0.3667, 0.275, 0.1375, 0.055, 0.0275, 0.01833, 0.01375, 0.0055, 0.00275]) #mol/L
CAdata = np.array([9.98, 9.89, 9.83, 9.78, 9.56, 8.97, 8.13, 7.43, 6.85, 4.65, 3.03]) #L/sec
CBtrue = np.array([0.022947221, 0.113692536, 0.169574834, 0.224828935, 0.439770554, 1.031390135, 1.869918699, 2.565055762, 3.150684932, 5.348837209, 6.96969697])
taudata = V/Qfdata
CBdata = np.round(CBtrue, 3)
noise = CBdata*np.random.normal(0, noise_level/100, CBdata.shape)
CBdatan = CBdata + noise
noiseA = CAdata*np.random.normal(0, noise_level/100, CAdata.shape)
CAdatan = CAdata + noiseA
rbtrue = CBtrue/tautrue
rbdatan = (CBdatan)/taudata
plt.figure(1, figsize = (5, 5))
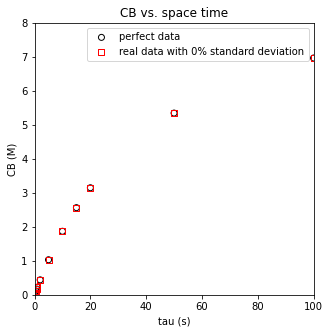
plt.scatter(tautrue, CBtrue, marker = 'o', color = 'none', edgecolor = 'black', label = 'perfect data')
plt.scatter(taudata, CBdatan, marker = 's', color = 'none', edgecolor = 'red', label = f'real data with {noise_level}% standard deviation')
plt.xlabel('tau (s)')
plt.ylabel('CB (M)')
plt.title('CB vs. space time')
plt.xlim(0, 100)
plt.ylim(0, 8)
plt.legend()
plt.show()
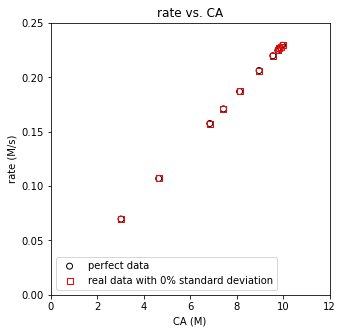
plt.figure(2, figsize = (5, 5))
plt.scatter(CAtrue, rbtrue, marker = 'o', color = 'none', edgecolor = 'black', label = 'perfect data')
plt.scatter(CAdatan, rbdatan, marker = 's', color = 'none', edgecolor = 'red', label = f'real data with {noise_level}% standard deviation')
plt.xlabel('CA (M)')
plt.ylabel('rate (M/s)')
plt.title('rate vs. CA')
plt.xlim(0, 12)
plt.ylim(0, 0.25)
plt.legend()
plt.show()
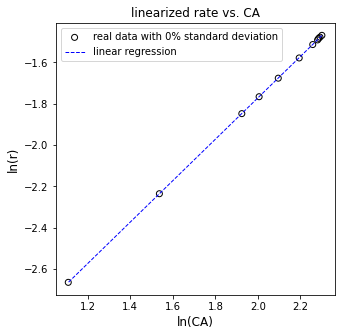
plt.figure(3, figsize = (5, 5))
plt.scatter(np.log(CAtrue), np.log(rbtrue), marker = 'o', color = 'none', edgecolor = 'black', label = 'perfect data')
plt.scatter(np.log(CAdatan), np.log(rbdatan), marker = 's', color = 'none', edgecolor = 'red', label = f'real data with {noise_level}% standard deviation')
plt.xlabel('ln(CA)')
plt.ylabel('ln(r)')
plt.title('linearized rate vs. CA')
plt.xlim(1.0, 2.4)
plt.ylim(-2.8, -1.4)
plt.legend()
plt.show()
display(np.vstack((CBtrue, CBdatan, (CBtrue - CBdatan)*100/CBtrue)).T)
display(np.vstack((rbtrue, rbdatan, (rbtrue - rbdatan)*100/rbtrue)).T)

array([[ 2.29472210e-02, 2.30000000e-02, -2.30001707e-01],
[ 1.13692536e-01, 1.14000000e-01, -2.70434640e-01],
[ 1.69574834e-01, 1.70000000e-01, -2.50724704e-01],
[ 2.24828935e-01, 2.25000000e-01, -7.60867368e-02],
[ 4.39770554e-01, 4.40000000e-01, -5.21740253e-02],
[ 1.03139014e+00, 1.03100000e+00, 3.78261326e-02],
[ 1.86991870e+00, 1.87000000e+00, -4.34783609e-03],
[ 2.56505576e+00, 2.56500000e+00, 2.17390986e-03],
[ 3.15068493e+00, 3.15100000e+00, -9.99998435e-03],
[ 5.34883721e+00, 5.34900000e+00, -3.04348391e-03],
[ 6.96969697e+00, 6.97000000e+00, -4.34782174e-03]])
array([[ 0.22947221, 0.23 , -0.23000171],
[ 0.22738507, 0.228 , -0.27043464],
[ 0.22609978, 0.22668727, -0.2598384 ],
[ 0.22482894, 0.225 , -0.07608674],
[ 0.21988528, 0.22 , -0.05217403],
[ 0.20627803, 0.2062 , 0.03782613],
[ 0.18699187, 0.187 , -0.00434784],
[ 0.17100372, 0.17096891, 0.02035515],
[ 0.15753425, 0.15755 , -0.00999998],
[ 0.10697674, 0.10698 , -0.00304348],
[ 0.06969697, 0.0697 , -0.00434782]])
##These are textbook linear least squares formulas that I got from my statistics book
##They are calculating statistics on the fit, standard errors, confidence intervals, SSE, SST, R2, etc.
X = np.vander(np.log(CAdatan),2) #X matrix, powers of measured ln(CA)
Y = np.log(rbdatan) #Y vector, values of measured ln(r)
A = np.linalg.solve(X.T@X, X.T@Y) #regression coefficients, slope and intercept
SSE = (Y - X@A).T@(Y-X@A) #Residual sum of squares, equivalent to sum (y_i - y_hat_i)^2
SST = sum((Y - np.mean(Y))**2) #Total sum of squares, SST = sum(y_i - mean(y))^2
R2 = 1 - SSE/SST #R2
s2 = SSE/(len(Y) - len(A)) #essentially, a standard deviation approximation for variance, sigma^2
cov = s2*np.linalg.inv((X.T@X)) #covariance matrix
se = np.sqrt(abs(cov)) #standard error matrix; diagonal elements are standard error in each coefficient
ci = stats.t.ppf(0.975, len(Y) - len(A))*se #confidence intervals
Ypred = X@A #predicted values of Y
print(A)
print(f'The R2 value for this fit is {R2:3.3f}')
print(f'The regressed order is {A[0]:3.3f} plus/minus {ci[0,0]:3.4f} and the regressed value of ln(k) is {A[1]:3.3f} plus/minus {ci[1,1]:3.3f}')
print(f'The rate constant is approximately {np.exp(A[1]):3.3f} s^-1')
plt.figure(3, figsize = (5, 5))
plt.scatter(np.log(CAdatan), np.log(rbdatan), marker = 'o', color = 'none', edgecolor = 'black', label = f'real data with {noise_level}% standard deviation')
plt.plot(np.log(CAdatan), Ypred, color = 'blue', linestyle = 'dashed', linewidth = 1, label = 'linear regression')
plt.xlabel('ln(CA)', fontsize = 12)
plt.ylabel('ln(r)', fontsize = 12)
plt.title('linearized rate vs. CA')
#plt.xlim(1.0, 2.5)
#plt.xticks(np.arange(1.0, 2.51, 0.25))
#plt.ylim(-1.4, -2.8)
plt.legend()
plt.show()
[ 1.00115817 -3.77386275]
The R2 value for this fit is 1.000
The regressed order is 1.001 plus/minus 0.0019 and the regressed value of ln(k) is -3.774 plus/minus 0.004
The rate constant is approximately 0.023 s^-1
Example Problem 02#
Next, we’ll consider a data set where not much has been done systematically.
Someone decided to perform a “kinetic study” of the following reaction in a CSTR.
We propose that the rate of reaction depends on concentrations of A and B in some power law model:
Our technician made some interesting choices in how they ran the experiment. They apparently varied space time (by varying feed flowrate), and they also seem to have been randomly changing the concentrations of both A and B in the feed with every change in residence time. We’d love to get an estimate for k, \(\alpha\), and \(\beta\), but it looks like it might be challenging considering the way the experiment was performed.
Never fear; we know how to wrangle data…
The data are in an attached CSV file. The bit of code below opens that file and convert it into a numpy array.
import pandas as pd
dataframe = pd.read_csv("CSTRdata.csv")
dataframe
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_15136\852484166.py in <cell line: 2>()
1 import pandas as pd
----> 2 dataframe = pd.read_csv("CSTRdata.csv")
3 dataframe
~\anaconda3\lib\site-packages\pandas\util\_decorators.py in wrapper(*args, **kwargs)
309 stacklevel=stacklevel,
310 )
--> 311 return func(*args, **kwargs)
312
313 return wrapper
~\anaconda3\lib\site-packages\pandas\io\parsers\readers.py in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, error_bad_lines, warn_bad_lines, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options)
678 kwds.update(kwds_defaults)
679
--> 680 return _read(filepath_or_buffer, kwds)
681
682
~\anaconda3\lib\site-packages\pandas\io\parsers\readers.py in _read(filepath_or_buffer, kwds)
573
574 # Create the parser.
--> 575 parser = TextFileReader(filepath_or_buffer, **kwds)
576
577 if chunksize or iterator:
~\anaconda3\lib\site-packages\pandas\io\parsers\readers.py in __init__(self, f, engine, **kwds)
932
933 self.handles: IOHandles | None = None
--> 934 self._engine = self._make_engine(f, self.engine)
935
936 def close(self):
~\anaconda3\lib\site-packages\pandas\io\parsers\readers.py in _make_engine(self, f, engine)
1216 # "Union[str, PathLike[str], ReadCsvBuffer[bytes], ReadCsvBuffer[str]]"
1217 # , "str", "bool", "Any", "Any", "Any", "Any", "Any"
-> 1218 self.handles = get_handle( # type: ignore[call-overload]
1219 f,
1220 mode,
~\anaconda3\lib\site-packages\pandas\io\common.py in get_handle(path_or_buf, mode, encoding, compression, memory_map, is_text, errors, storage_options)
784 if ioargs.encoding and "b" not in ioargs.mode:
785 # Encoding
--> 786 handle = open(
787 handle,
788 ioargs.mode,
FileNotFoundError: [Errno 2] No such file or directory: 'CSTRdata.csv'
import csv
file = open("CSTRdata.csv")
csvreader = csv.reader(file)
header = []
header = next(csvreader)
rows = []
for row in csvreader:
rows.append(row)
file.close()
data = np.array(rows, dtype = 'float')
Parameter Estimation Using Nonlinear Regression#
One solution is to use nonlinear regression to minimize an objective function created by calculating the residual sum of squares between measured rates and model predicted rates. Example below
taudata = data[:,0]
CAfdata = data[:,1]
CBfdata = data[:,2]
CCfdata = data[:,3]
XAdata = data[:,4]
CAdata = CAfdata*(1 - XAdata)
CBdata = CBfdata - 2*CAfdata*XAdata
CCdata = CCfdata + 3*CAfdata*XAdata
rdata = CCdata/3/taudata
meas = np.vstack((CAdata, CBdata, CCdata)).T
def rates_CSTR(par, meas):
k = par[0]
alpha = par[1]
beta = par[2]
CA = meas[:,0]
CB = meas[:,1]
rmod = k*CA**alpha*CB**beta
return rmod
par0 = [1, 1,1]
OBJ = lambda par: np.sum((rates_CSTR(par, meas) - rdata)**2)
ans = opt.minimize(OBJ, par0)
ans
fun: 2.3554880977158813e-13
hess_inv: array([[ 0.83416139, 1.38191673, -2.22554533],
[ 1.38191673, 3.05170545, -3.48387855],
[-2.22554533, -3.48387855, 6.06915988]])
jac: array([-6.55642979e-07, 3.95426875e-08, -2.07312503e-07])
message: 'Optimization terminated successfully.'
nfev: 100
nit: 21
njev: 25
status: 0
success: True
x: array([0.34699937, 0.99999891, 2.00000167])
Multiple Linear Regression#
Alternatively, we can linearize this problem. We know that the rate of reaction should be given by a power law:
This can be linearized as usual by taking logarithms of both sides to give:
Putting this into matrix form, we would have:
Where
X is a vandermonde type matrix in which each row is:
Where
And where Y is a vector of our measurements, in this case, ln(r), so each entry is given by:
With those definitions, we can perform linear regression as usual. Below, I create the X matrix manually because I don’t know offhand of an automated way to generate the X matrix for multiple linear regression. Once that is done, you solve the least squares problem as usual:
X = np.ones((len(rdata),3))
X[:,0] = np.log(CAdata)
X[:,1] = np.log(CBdata)
Y = np.log(rdata)
A = np.linalg.solve(X.T@X, X.T@Y)
Ypred = X@A
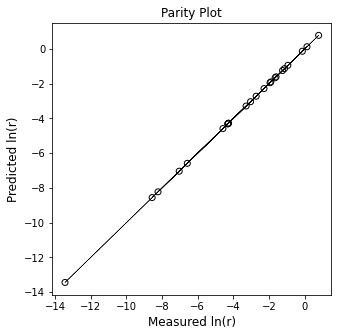
print(f'Order in A is {A[0]:3.2f}, order in B is {A[1]:3.2f}, rate constant is {np.exp(A[2]):3.2f} L^2/M^2/min')
plt.figure(1, figsize = (5, 5))
plt.scatter(Y, Ypred, marker = 'o', color = 'none', edgecolor = 'black')
plt.plot(Y, Y, linestyle = 'solid', color = 'black', linewidth = 0.5)
plt.title('Parity Plot')
plt.xlabel('Measured ln(r)', fontsize = 12)
plt.ylabel('Predicted ln(r)', fontsize = 12)
plt.show()
Order in A is 1.00, order in B is 2.00, rate constant is 0.35 L^2/M^2/min