
Kinetics III
Contents
Kinetics III#
We continue kinetic analysis. Now that we have a basic understanding of the methods (least squares minimization, linearization, linear regression, etc.), we will work through noisy data (i.e., real data) obtained in a constant volume batch reactor. We introduce a few tools for managing noisy data, and we consider the method of excess. We’ll also develop some metrics that complement the sum of squares in helping us to understand goodness of fit; these include the coefficient of determination (R2) and confidence intervals on parameter estimates.
import numpy as np
import matplotlib.pyplot as plt
import scipy.optimize as opt
import scipy.stats as stats
Example Problem 01#
Analysis of “Real” Data Collected in a Constant Volume Batch Reactor.
The following reaction is carried out in a well-mixed, constant volume batch reactor. The concentration of species A and B in the tank are initially 0.05M and 0.5M, respectively. The fluid inside of the reactor has constant density.
You measure the concentration of species A in this reactor, monitoring how it changes with time. The data you collect are given in the table below.
time (min) |
C\(_A\) \(\times 10^{2}\) (mol/L) |
|---|---|
0 |
4.81 |
25 |
4.52 |
50 |
3.86 |
75 |
3.30 |
100 |
3.21 |
125 |
2.73 |
150 |
2.53 |
175 |
2.43 |
200 |
2.31 |
225 |
2.01 |
250 |
1.96 |
275 |
1.88 |
300 |
1.70 |
Assuming the rate law is described by power law kinetics,
where \(\alpha\) is an integer and \(\beta = 1\), determine the reaction order in A and the rate constant for this reaction.
Solution to Example Problem 01#
Before we start, it’s important to point out something about regression and parameter estimation. Here, we are looking for the order with respect to species A. If we’re trying to extract that order from data, this is easiest to do if we’ve performed an experiment where we are only varying the concentration of species A and watching how the system responds. In a batch reactor, this is tricky because the concentration of species A and species B will both generally change as a function of time since both species are reactants.
The way we usually handle this is by performing the experiment in such a way that the only the concentration of interest varies (in this case, species A) while the other remains fixed. A common way to do this is using the method of excess. This entails having one reactant present in a large excess so that its concentration does not significantly change over the course of the experiment. Here, that is done with species B. It’s initial concentration is 0.5M, whereas the initial concentration of A is 0.05M. Clearly, A is the limiting reactant, and if we convert 100% of A, we would only decrease the concentration of species B by 10% to 0.45M. This is typical of method of excess. The change in concentration of species B over the course of the experiment is insignificant compared to the change in concentration of species A. This allows us to extract the dependence on species A from our data.
In this case, we start with the following general rate expression:
We know that \(\beta\) = 1, so:
Since in this experiment \(C_B \approx C_{B0}\):
Since \(C_{B0}\) is constant, we lump it it with the rate constant to get:
i.e., a rate expression that only depends on the concentration of A. We just have to recall that the rate constate we estimate from this model, \(k^\prime\) is actually defined as:
So if we want to get the true rate constant, \(k\), we have to account for that dependence in the lumped constant in our final analysis.
tdata = np.array([0, 25, 50, 75, 100, 125, 150, 175, 200, 225, 250, 275, 300]) #time in minutes
CAdata =np.array([0.0481, 0.0452, 0.0386, 0.0330, 0.0321, 0.0273, 0.0253, 0.0243, 0.0231, 0.0201, 0.0196, 0.0188, 0.0170])
#Concentrations in moles per liter
plt.figure(1, figsize = (5, 5))
plt.title('Noisy data for A + B --> C', fontsize = 14)
plt.scatter(tdata, CAdata, marker = 's', color = 'none', edgecolor = 'black', label = 'CA')
plt.ylim(0, 0.05)
plt.xlabel('time (min)', fontsize = 12)
plt.ylabel('CA (M)', fontsize = 12)
plt.legend()
plt.show()
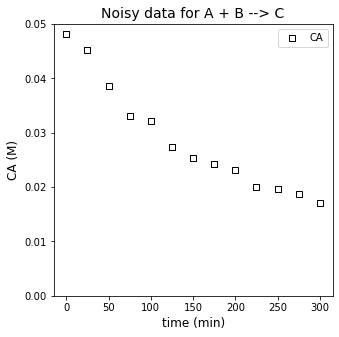
Now we attempt to extract the rate constant, k, and reaction order in A, \(\alpha\), from our experimental data. We are working with a power law model based on a lumped rate constant:
For a constant volume batch reactor, the balance on species A is therefore:
We have options as usual. Let’s start with a differential analysis and then go to an integral analysis.
Differential Analysis#
The beauty of the differential analysis is that I can use it to estimate the reaction order when I really don’t know one. We know that it can introduce some imprecision because of limitations in finite difference approximations, but it is a useful way to start an analysis. So let’s go ahead and approximate the derivative in the above material balance using a forward difference method.
With that, we would have a set of reaction rates at a corresponding set of CA values, and so we can consider how rate scales with concentration:
Which can be linearized using logarithms:
DCA = np.diff(CAdata)
Dt = np.diff(tdata)
DCADT = DCA/Dt
r = -1*DCADT
print(r)
len(r)
[1.16e-04 2.64e-04 2.24e-04 3.60e-05 1.92e-04 8.00e-05 4.00e-05 4.80e-05
1.20e-04 2.00e-05 3.20e-05 7.20e-05]
12
Recall that we have to use two data points to estimate a derivative, so our set of 13 measurments gives us 12 estimated derivatives using a forward difference method only.
Now let’s plot those rates against the corresponding concentrations on logarithmic axes to get a sense of the reaction order…
ydata = np.log(r)
xdata = np.log(CAdata[:-1])
plt.figure(1, figsize = (5, 5))
plt.scatter(xdata, ydata, marker = 's', color = 'none', edgecolor = 'black', label = 'CA')
plt.xlabel('ln(CA (M))', fontsize = 12)
plt.ylabel('ln(rate (mol/L/min))', fontsize = 12)
plt.xlim(-4.5, -2.5)
plt.xticks(np.arange(-4.5, -2.49, 0.5))
plt.minorticks_on()
plt.ylim(-11, -8)
plt.show()

Yikes! Let’s see what linear regression gets us in terms of the reaction order and rate constant…
A = np.polyfit(xdata, ydata, 1)
order = A[0]
k = np.exp(A[1])
print(f'α = {order:0.2f}, k = {k:0.3f}')
plt.figure(1, figsize = (5, 5))
plt.scatter(xdata, ydata, marker = 's', color = 'none', edgecolor = 'black', label = 'CA')
plt.plot(xdata, np.polyval(A, xdata), color = 'black', linestyle = 'dashed')
plt.xlabel('ln(CA (M))', fontsize = 12)
plt.ylabel('ln(rate (mol/L/min))', fontsize = 12)
plt.xlim(-4.5, -2.5)
plt.xticks(np.arange(-4.5, -2.49, 0.5))
plt.minorticks_on()
plt.ylim(-11, -8)
plt.show()
plt.figure(1, figsize = (5, 5))
plt.scatter(xdata, (ydata - np.polyval(A, xdata)), marker = 's', color = 'none', edgecolor = 'black', label = 'CA')
plt.hlines(0, min(xdata), max(xdata), color = 'black', linestyle = 'dashed')
plt.xlabel('CA', fontsize = 12)
plt.ylabel('Residual)', fontsize = 12)
plt.xlim(-4.0, -3.0)
plt.show()
α = 1.75, k = 0.040
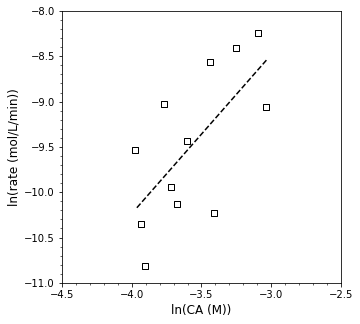
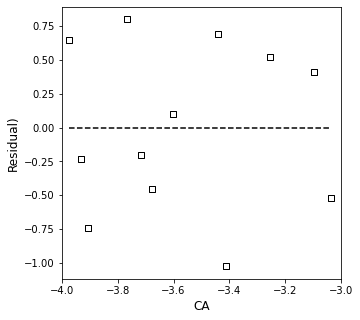
Clearly, that is a rough fit. It suggests that my reaction order is 1.75 and that the rate constant is 0.04…but the data is all over the place. Let’s add a bit more quantitative information information to this. One thing that might be useful to us is knowing the residual sum of squares for this fit. We have already seen how to calculate residual sum of squares in L29 and R10:
As with many Python tools, np.polyfit() is more fully featured than the default usage we implemented above. If we request full output, it will return the minimum sum of squares (among other things).
A, SSE, rank, sing, rcond = np.polyfit(xdata, ydata, 1, full = True)
order = A[0]
k = np.exp(A[1])
print(f'α = {order:0.2f}, k = {k:0.3f}, Minimum SSE = {SSE[0]:0.2f}')
# plt.figure(1, figsize = (5, 5))
# plt.scatter(xdata, ydata, marker = 's', color = 'none', edgecolor = 'black', label = 'CA')
# plt.plot(xdata, np.polyval(A, xdata), color = 'black', linestyle = 'dashed')
# plt.xlabel('ln(CA (M))', fontsize = 12)
# plt.ylabel('ln(rate (mol/L/min))', fontsize = 12)
# plt.xlim(-4.5, -2.5)
# plt.xticks(np.arange(-4.5, -2.49, 0.5))
# plt.minorticks_on()
# plt.ylim(-11, -8)
# plt.show()
# plt.figure(1, figsize = (5, 5))
# plt.scatter(xdata, (ydata - np.polyval(A, xdata)), marker = 's', color = 'none', edgecolor = 'black', label = 'CA')
# plt.hlines(0, min(xdata), max(xdata), color = 'black', linestyle = 'dashed')
# plt.xlabel('CA', fontsize = 12)
# plt.ylabel('Residual)', fontsize = 12)
# plt.xlim(-4.0, -3.0)
# plt.show()
α = 1.75, k = 0.040, Minimum SSE = 4.19
One issue with the Residual Sum of Squares as presented here is that it is an “extensive” quantity of sorts: it will generally get larger as a) we make more measurements and b) we measure larger quantities. So the absolute value of SSE is hard to interpret. Some complementary metrics include the Mean Square Error (MSE), which captures the average error in an individual measurement:
The MSE still will depend on the size of measurements that we are making, but it at least is normalized to an individual measurement. If we take the square root of the MSE, then we have the root mean square error, which gives us an estimate of the average absolute error in each measurement; it is also dependent on the size of the measurement that we are making, but it is informative as to goodness of fit as it is relatively easy to relate it to the magnitude of the measurements.
A similar concept is the Mean Absolute Error, which gives us a sense of average displacement between the model and the measurements. MAE is defined as:
Another thing of interest would be the coefficient of determination (\(R^2\)), which is intensive in that it conveys the same information (goodness of fit) no matter how many measurements we take or how large (or small) those measurements are. Most of us are used to getting an \(R^2\) directly alongside a trendline in Excel; they are straightforward to calculate. The general formula for the coefficient of determination is:
We calculate the residual sum of squares (SSE) using the standard formula:
The total sum of squares (SST) is a related metric that evaluates the amount of error between the measured values and the mean of the measured values:
In the expressions above, \(\hat{y}_i\) is the model prediction for the observable \(y\) at condition \(t_i\). \(\bar{y}\) is the mean of all measured values for the observable \(y\).
Now that we have these definitions, let’s go ahead and add the MSE and Coefficient of Determination to our output.
A, SSE, rank, sing, rcond = np.polyfit(xdata, ydata, 1, full = True)
ypred = np.polyval(A, xdata)
SSE = SSE[0]
α = A[0]
k = np.exp(A[1])
Ndata = len(xdata)
MSE = SSE/Ndata
RMSE = np.sqrt(MSE)
MAE = 1/Ndata*np.sum(np.abs(ydata - ypred))
ybar = np.mean(ydata)
SST = np.sum((ydata - ybar)**2)
R2 = 1 - SSE/SST
labels = ['k', 'α', 'SSE', 'MSE', 'RMSE', 'MAE', 'R2']
values = [k, α, SSE, MSE, RMSE, MAE, R2]
for label, value in zip(labels, values):
print(f'{label:4s} = {value:0.2f}')
# plt.figure(1, figsize = (5, 5))
# plt.scatter(xdata, ydata, marker = 's', color = 'none', edgecolor = 'black', label = 'CA')
# plt.plot(xdata, np.polyval(A, xdata), color = 'black', linestyle = 'dashed')
# plt.xlabel('ln(CA (M))', fontsize = 12)
# plt.ylabel('ln(rate (mol/L/min))', fontsize = 12)
# plt.xlim(-4.5, -2.5)
# plt.xticks(np.arange(-4.5, -2.49, 0.5))
# plt.minorticks_on()
# plt.ylim(-11, -8)
# plt.show()
# plt.figure(1, figsize = (5, 5))
# plt.scatter(xdata, (ydata - np.polyval(A, xdata)), marker = 's', color = 'none', edgecolor = 'black', label = 'CA')
# plt.hlines(0, min(xdata), max(xdata), color = 'black', linestyle = 'dashed')
# plt.xlabel('CA', fontsize = 12)
# plt.ylabel('Residual)', fontsize = 12)
# plt.xlim(-4.0, -3.0)
# plt.show()
k = 0.04
α = 1.75
SSE = 4.19
MSE = 0.35
RMSE = 0.59
MAE = 0.53
R2 = 0.45
There is one more useful piece of information we can get out of the linear regression routine from polyfit – we can use it to estimate the confidence intervals on the parameters that we have estimated (\(\alpha\), and k). Confidence intervals give us a sense of how much we trust the parameters that we have estracted from the data. You may recall the calculation of confidence intervals from your statistics course. The first step is to caculate the standard error in the slope and intercept of our regression – this requires us to estimate the covariance matrix.
The standard error in our regressed parameters is given by the diagonal elements in the covariance matrix:
Noting that this may throw a warning if off-diagonal elements of the covariance matrix are negative. From that, we get the standard error in the slope from se[0,0] and the standard error in the intercept from se[1,1], i.e., the diagonal elements.
If you want to calculate confidence intervals, they are given by:
np.polyfit() will return the Covariance matrix if we request it (though we have to turn off full output. See below; we now generate a covariance matrix and use it to get confidence intervals on the parameters.
A, SSE, rank, sing, rcond = np.polyfit(xdata, ydata, 1, full = True)
A, COV = np.polyfit(xdata, ydata, 1, full = False, cov = True)
ypred = np.polyval(A, xdata)
SSE = SSE[0]
α = A[0]
k = np.exp(A[1])
Ndata = len(xdata)
MSE = SSE/Ndata
RMSE = np.sqrt(MSE)
MAE = 1/Ndata*np.sum(np.abs(ydata - ypred))
ybar = np.mean(ydata)
SST = np.sum((ydata - ybar)**2)
R2 = 1 - SSE/SST
DOF = len(ydata) - len(A)
SEm = np.sqrt(COV[0, 0])
SEb = np.sqrt(COV[1, 1])
tval = stats.t.ppf(0.975, DOF)
CIm = SEm*tval
CIb = SEb*tval
llb = A[1] - CIb
ulb = A[1] + CIb
kll = np.exp(llb)
kul = np.exp(ulb)
labels = ['k', 'α', 'SSE', 'MSE', 'RMSE', 'MAE', 'R2']
values = [k, α, SSE, MSE, RMSE, MAE, R2]
for label, value in zip(labels, values):
if label == 'k':
print(f'{label:s} is between {kll:0.2E} and {kul:0.2f} but I\'m sure it is {value:0.2f}...')
elif label == 'α':
print(f'{label:4s} = {value:0.2f} +/- {CIm:0.2f}')
else:
print(f'{label:4s} = {value:0.2f}')
# plt.figure(1, figsize = (5, 5))
# plt.scatter(xdata, ydata, marker = 's', color = 'none', edgecolor = 'black', label = 'CA')
# plt.plot(xdata, np.polyval(A, xdata), color = 'black', linestyle = 'dashed')
# plt.xlabel('ln(CA (M))', fontsize = 12)
# plt.ylabel('ln(rate (mol/L/min))', fontsize = 12)
# plt.xlim(-4.5, -2.5)
# plt.xticks(np.arange(-4.5, -2.49, 0.5))
# plt.minorticks_on()
# plt.ylim(-11, -8)
# plt.show()
# plt.figure(1, figsize = (5, 5))
# plt.scatter(xdata, (ydata - np.polyval(A, xdata)), marker = 's', color = 'none', edgecolor = 'black', label = 'CA')
# plt.hlines(0, min(xdata), max(xdata), color = 'black', linestyle = 'dashed')
# plt.xlabel('CA', fontsize = 12)
# plt.ylabel('Residual)', fontsize = 12)
# plt.xlim(-4.0, -3.0)
# plt.show()
k is between 3.12E-04 and 5.11 but I'm sure it is 0.04...
α = 1.75 +/- 1.35
SSE = 4.19
MSE = 0.35
RMSE = 0.59
MAE = 0.53
R2 = 0.45
This is terrible!!!
What’s going on here? As we saw in L28, taking finite differences introduces imprecision even in perfect data. Here, we have real (well, simulated real) data, where there is actual uncertainty and noise in the measurements. Sometimes our measurements are higher or lower than the “true” value at that time, and this compounds the uncertainty in the approximation that derivatives are constant when we use finite difference approximations.
Still, a differential analysis can be very useful…we can do a little better if we smooth the data before we estimate the derivative of that data. One way that we can do that by fitting a polynomial to the data set. We have to recognize that this polynomial fit is meaningless in a physical sense, it is just a way for us to develop a continuous, well-behaved function that empirically captures how concentration decreases with time. Once we have that, we can take the true derivative of the polynomial (not a finite difference of data), and we can use that to estimate rate of reaction and thus reaction orders. First, we fit the polynomial. I’ll use polyfit here because it makes it easy to adjust the order of the fit and display the results. Note that this below is mimicing what you’d get by “increasing polynomial order” in an Excel trendline.
I find a third order polynomial does a good job of smoothing out the trend without fitting the noise, so we’ll use that to provide a polynomial approximation of how concentration changes with time.
tdata = np.array([0, 25, 50, 75, 100, 125, 150, 175, 200, 225, 250, 275, 300]) #time in minutes
CAdata =np.array([0.0481, 0.0452, 0.0386, 0.0330, 0.0321, 0.0273, 0.0253, 0.0243, 0.0231, 0.0201, 0.0196, 0.0188, 0.0170])
#Concentrations in moles per liter
A = np.polyfit(tdata, CAdata, 3)
plt.figure(1, figsize = (5, 5))
plt.scatter(tdata, CAdata, marker = 's', color = 'none', edgecolor = 'black', label = 'CA')
plt.plot(tdata, np.polyval(A, tdata), color = 'black', linestyle = 'dashed')
plt.xlabel('time (min)', fontsize = 12)
plt.ylabel('CA (mol/L)', fontsize = 12)
plt.ylim(0, 0.05)
plt.legend()
plt.show()
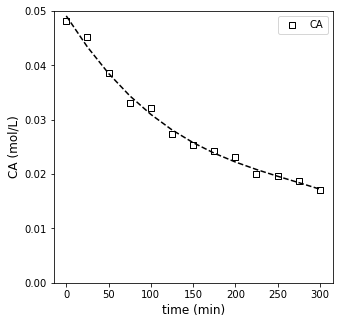
Numpy has some nice tools that allow us to take the derivative of a polynomial once we’ve generated it:
derivatives = np.polyder(A, m = 1)
rate_estimates = -1*np.polyval(derivatives, tdata)
Now that we have estimated the rates by taking a derivative of the polynomial approximation, let’s try our linearization and regression again.
ydata = np.log(rate_estimates)
xdata = np.log(CAdata)
A, SSE, rank, sing, rcond = np.polyfit(xdata, ydata, 1, full = True)
A, COV = np.polyfit(xdata, ydata, 1, full = False, cov = True)
ypred = np.polyval(A, xdata)
SSE = SSE[0]
α = A[0]
k = np.exp(A[1])
Ndata = len(xdata)
MSE = SSE/Ndata
RMSE = np.sqrt(MSE)
MAE = 1/Ndata*np.sum(np.abs(ydata - ypred))
ybar = np.mean(ydata)
SST = np.sum((ydata - ybar)**2)
R2 = 1 - SSE/SST
DOF = len(ydata) - len(A)
SEm = np.sqrt(COV[0, 0])
SEb = np.sqrt(COV[1, 1])
tval = stats.t.ppf(0.975, DOF)
CIm = SEm*tval
CIb = SEb*tval
llb = A[1] - CIb
ulb = A[1] + CIb
kll = np.exp(llb)
kul = np.exp(ulb)
labels = ['k', 'α', 'SSE', 'MSE', 'RMSE', 'MAE', 'R2']
values = [k, α, SSE, MSE, RMSE, MAE, R2]
for label, value in zip(labels, values):
if label == 'k':
print(f'{label:s} is between {kll:0.2E} and {kul:0.2f} but I\'m sure it is {value:0.2f}...')
elif label == 'α':
print(f'{label:4s} = {value:0.2f} +/- {CIm:0.2f}')
else:
print(f'{label:4s} = {value:0.2f}')
plt.figure(1, figsize = (5, 5))
plt.scatter(xdata, ydata, marker = 's', color = 'none', edgecolor = 'black', label = 'CA')
plt.plot(xdata, np.polyval(A, xdata), color = 'black', linestyle = 'dashed')
plt.xlabel('ln(CA (M))', fontsize = 12)
plt.ylabel('ln(rate (mol/L/min))', fontsize = 12)
plt.xlim(-4.5, -2.5)
plt.xticks(np.arange(-4.5, -2.49, 0.5))
plt.minorticks_on()
plt.ylim(-11, -8)
plt.show()
plt.figure(1, figsize = (5, 5))
plt.scatter(xdata, (ydata - np.polyval(A, xdata)), marker = 's', color = 'none', edgecolor = 'black', label = 'CA')
plt.hlines(0, min(xdata), max(xdata), color = 'black', linestyle = 'dashed')
plt.xlabel('CA', fontsize = 12)
plt.ylabel('Residual)', fontsize = 12)
plt.xlim(-4.0, -3.0)
plt.show()
k is between 2.45E-02 and 0.10 but I'm sure it is 0.05...
α = 1.75 +/- 0.20
SSE = 0.12
MSE = 0.01
RMSE = 0.10
MAE = 0.08
R2 = 0.97
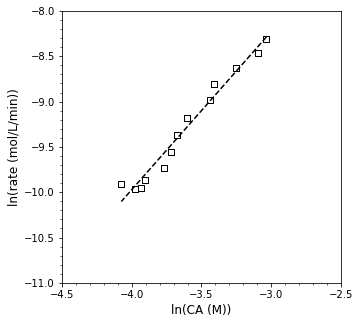
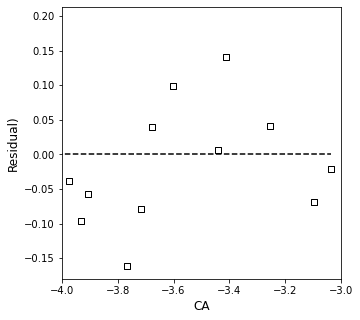
OK, so, the take home: the estimates of our order and rate constant didn’t change much but their precision did improve, which greatly increases my confidence. It is easier to accept the trend we see here because the fit is so much better. Based on that and the confidence intervals, we find that the reaction order estimate is:
If we’re restricting to integer orders, I’m going to guess these are probably second order kinetics, but let’s work through an integral analysis and see if that bears out.
Based on this approach, the rate constant is obtained from the y-intercept, and we get a value of:
\(k^\prime = 0.05\)
But the confidence intervals are such that it probably is somewhere between 0.02 and 0.1 L/mol/min.
Integral Analysis with nonlinear Regression#
We’ll start with the balance
And we’ll guess integer orders for \(\alpha\) and see what shakes out. I’m going to try \(\alpha\) = 1, 2, and 3 in this example.
First Order Solution#
For a first order reaction, the material balance on A in a constant volume reactor becomes:
This is a separable ODE, so we’ll solve it by hand.
Which gives:
Second Order Solution#
For a second order reaction, the material balance on A in a constant volume reactor becomes:
This is a separable ODE, so we’ll solve it by hand.
Which gives:
We can rearrange to get:
Third Order Solution#
For a third order reaction, the material balance on A in a constant volume reactor becomes:
This is a separable ODE, so we’ll solve it by hand.
Which gives:
We can rearrange to get:
Summary of integrated models#
To summarize, we have 3 models to compare to our data:
First Order: \(C_A = C_{A0}\exp\left(-k^\prime t\right)\)
Second Order: \(\frac{1}{C_A} = \frac{1}{C_{A0}} + k^\prime t\)
Third Order: \(C_A = \left(\frac{1}{{C_{A0}}^2} + 2k^\prime t\right)^{-\frac{1}{2}}\)
Now let’s overlay those models with our data and run an optimization (nonlinear least squares) to find the best value of the lumped rate constant. Then, we’ll take a look at how well the model fits our data.
Nonlinear Least Squares#
As we considered in L29, the mathematically rigorous way to find the best value of the rate constant is to find the one that gives the “line of best fit” by minimizing the residual sum of squares:
Mean square error is defined as:
It allows us to normalize error to the number of measurments made. The root mean square is defined as:
And the Mean Absolute Error is defined as:
In addition to the SSE, we can also calculate the total sum of squares:
This can be used to get a coefficient of determination:
If you want to obtain estimates of standard error in the slope and y intercept that you regress, you need to estimate the covariance matrix. First, we estimate the variance, \(\sigma^2\) with the following:
and:
Where \(n_m\) is the number of measurements and \(n_p\) is the number of regressed parameters. This is also known as the “degrees of freedom” in our regression.
With that, we can estimate the covariance matrix from the Jacobian Matrix:
The standard error in our regressed parameters is given by the diagonal elements in the following matrix:
Noting that this may throw a warning if off-diagonal elements of the covariance matrix are negative.
From that, we get the standard error in the slope from se[0,0] and the standard error in the intercept from se[1,1], i.e., the diagonal elements.
If you want to calculate confidence intervals, they are given by:
First Order Nonlinear Regression#
def OBJONE(k):
CA0 = 0.05 #mol/L
tDATA = np.array([0, 25, 50, 75, 100, 125, 150, 175, 200, 225, 250, 275, 300]) #time in minutes
CADATA = np.array([0.0481, 0.0452, 0.0386, 0.0330, 0.0321, 0.0273, 0.0253, 0.0243, 0.0231, 0.0201, 0.0196, 0.0188, 0.0170])
CAFIRST = CA0*np.exp(- k*tDATA)
RESID = CADATA - CAFIRST
SSE = np.sum(RESID**2)
return SSE
def JACONE(k):
CA0 = 0.05 #mol/L
tDATA = np.array([0, 25, 50, 75, 100, 125, 150, 175, 200, 225, 250, 275, 300]) #time in minutes
CADATA = np.array([0.0481, 0.0452, 0.0386, 0.0330, 0.0321, 0.0273, 0.0253, 0.0243, 0.0231, 0.0201, 0.0196, 0.0188, 0.0170])
JAC = -CA0*tdata*np.exp(- k*tDATA)
return JAC
ans1 = opt.minimize_scalar(OBJONE, method = 'Brent', bracket = [0.01, 0.05])
SSE1 = ans1.fun
k1 = ans1.x
#Calculate result for best fit first order model
tsmooth = np.linspace(0, max(tdata), 100)
CA0 = 0.05 #mol/L
CAPRED1 = CA0*np.exp(-k1*tdata)
CMOD1 = CA0*np.exp(-k1*tsmooth)
JAC1 = JACONE(k1)
Ndata = len(tdata)
DOF = Ndata - 1
MSE1 = SSE1/Ndata
RMSE1 = np.sqrt(MSE1)
MAE1 = 1/Ndata*np.sum(np.abs(CAdata - CAPRED1))
COV1 = SSE1/DOF*1/(JAC1.T@JAC1)
SEk1 = np.sqrt(COV1)
tval = stats.t.ppf(0.975, DOF)
CIk1 = tval*SEk1
CAbar = np.mean(CAdata)
SST1 = np.sum((CAdata - CAbar)**2)
R21 = 1 - SSE1/SST1
print('\n', ans_first, '\n')
labels = ['k', 'α', 'SSE', 'MSE', 'RMSE', 'MAE', 'R2']
values = [k1, 1, SSE1, MSE1, RMSE1, MAE1, R21]
for label, value in zip(labels, values):
if label == 'k':
print(f'{label:4s} = {value:0.2E} +/- {CIk:0.2E}')
else:
print(f'{label:4s} = {value:0.2E}')
#Overlay best fit model with data
plt.figure(1, figsize = (5, 5))
plt.scatter(tdata, CAdata, marker = 'o', color = 'none', edgecolor = 'black', label = 'CA')
plt.plot(tsmooth, CMOD1, color = 'black', linestyle = 'dashed')
plt.title('First order nonlinear regression')
plt.xlabel('time (min))', fontsize = 12)
plt.ylabel('CA (M))', fontsize = 12)
plt.xlim(0, max(tdata))
plt.ylim(0, 0.06)
plt.show()
plt.figure(2, figsize = (5, 5))
plt.scatter(tdata, (CAdata - CAPRED1), marker = 'o', color = 'none', edgecolor = 'black', label = 'CA')
plt.hlines(0, 0, max(tdata), color = 'black', linestyle = 'dashed')
plt.title('Residual Plot for First order')
plt.xlabel('time (min))', fontsize = 12)
plt.ylabel('Residual (M))', fontsize = 12)
plt.xlim(0, max(tdata))
plt.show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_5040\3841581823.py in <cell line: 26>()
24 R21 = 1 - SSE1/SST1
25
---> 26 print('\n', ans_first, '\n')
27
28 labels = ['k', 'α', 'SSE', 'MSE', 'RMSE', 'MAE', 'R2']
NameError: name 'ans_first' is not defined
Now we have some quantitative assessments of goodness of fit. For real data, an \(R^2\) of 0.96 or so is pretty good, so for the moment, we’ll call this an acceptable fit.
Second Order Nonlinear Regression#
Now let’s see how a second order model fits the data. We’ll go ahead and regress the best fit rate constant, plot the result, and calculate some basic statistical data about goodness of fit.
def OBJTWO(k):
CA0 = 0.05 #mol/L
tDATA = np.array([0, 25, 50, 75, 100, 125, 150, 175, 200, 225, 250, 275, 300]) #time in minutes
CADATA = np.array([0.0481, 0.0452, 0.0386, 0.0330, 0.0321, 0.0273, 0.0253, 0.0243, 0.0231, 0.0201, 0.0196, 0.0188, 0.0170])
CASECOND = 1/(1/CA0 + k*tDATA)
RESID = CADATA - CASECOND
SSE = np.sum(RESID**2)
return SSE
def JACTWO(k):
CA0 = 0.05 #mol/L
tDATA = np.array([0, 25, 50, 75, 100, 125, 150, 175, 200, 225, 250, 275, 300]) #time in minutes
CADATA = np.array([0.0481, 0.0452, 0.0386, 0.0330, 0.0321, 0.0273, 0.0253, 0.0243, 0.0231, 0.0201, 0.0196, 0.0188, 0.0170])
JAC = -tdata/(1/CA0 + k*tdata)**2
return JAC
ans2 = opt.minimize_scalar(OBJTWO, method = 'Brent', bracket = [0.01, 0.05])
SSE2 = ans2.fun
k2 = ans2.x
#Calculate result for best fit first order model
tsmooth = np.linspace(0, max(tdata), 100)
CA0 = 0.05 #mol/L
CAPRED2 = 1/(1/CA0 + k2*tdata)
CMOD2 = 1/(1/CA0 + k2*tsmooth)
JAC2 = JACTWO(k2)
Ndata = len(tdata)
DOF = Ndata - 1
MSE2 = SSE2/Ndata
RMSE2 = np.sqrt(MSE2)
MAE2 = 1/Ndata*np.sum(np.abs(CAdata - CAPRED2))
COV2 = SSE2/DOF*1/(JAC2.T@JAC2)
SEk2 = np.sqrt(COV2)
tval = stats.t.ppf(0.975, DOF)
CIk2 = tval*SEk2
CAbar = np.mean(CAdata)
SST2 = np.sum((CAdata - CAbar)**2)
R22 = 1 - SSE2/SST2
print('\n', ans2, '\n')
labels = ['k', 'α', 'SSE', 'MSE', 'RMSE', 'MAE', 'R2']
values = [k2, 2, SSE2, MSE2, RMSE2, MAE2, R22]
for label, value in zip(labels, values):
if label == 'k':
print(f'{label:4s} = {value:0.2E} +/- {CIk2:0.2E}')
else:
print(f'{label:4s} = {value:0.2E}')
#Overlay best fit model with data
plt.figure(1, figsize = (5, 5))
plt.scatter(tdata, CAdata, marker = 'o', color = 'none', edgecolor = 'black', label = 'CA')
plt.plot(tsmooth, CMOD2, color = 'black', linestyle = 'dashed')
plt.title('Second Order Nonlinear Regression')
plt.xlabel('time (min))', fontsize = 12)
plt.ylabel('CA (M))', fontsize = 12)
plt.xlim(0, max(tdata))
plt.ylim(0, 0.06)
plt.show()
plt.figure(2, figsize = (5, 5))
plt.scatter(tdata, (CAdata - CAPRED2), marker = 'o', color = 'none', edgecolor = 'black', label = 'CA')
plt.hlines(0, 0, max(tdata), color = 'black', linestyle = 'dashed')
plt.title('Residual Plot for Second Order')
plt.xlabel('time (min))', fontsize = 12)
plt.ylabel('CA (M))', fontsize = 12)
plt.xlim(0, max(tdata))
plt.show()
fun: 1.3014231460548578e-05
nfev: 17
nit: 11
success: True
x: 0.12389199399645329
k = 1.24E-01 +/- 7.16E-03
α = 2.00E+00
SSE = 1.30E-05
MSE = 1.00E-06
RMSE = 1.00E-03
MAE = 8.29E-04
R2 = 9.89E-01
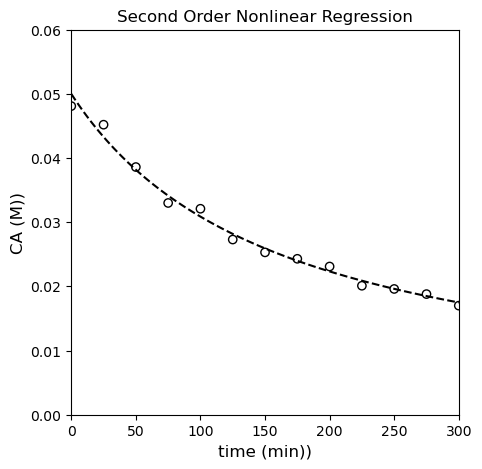
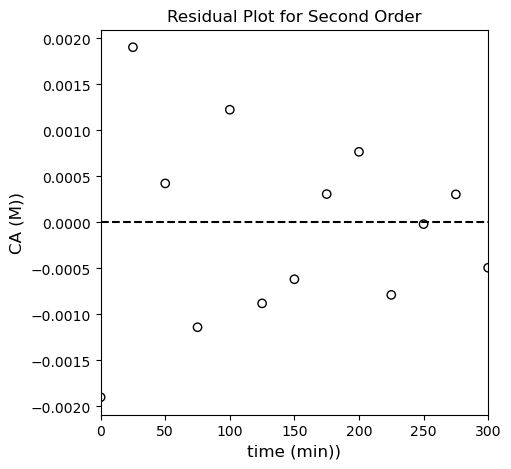
OK, by all metrics–visual, SSE, and \(R^2\), the second order model improves on the first order model. Is it the best? It’s hard to say for sure…let’s try the third order model and see how that goes.
def OBJTHREE(k):
CA0 = 0.05 #mol/L
tDATA = np.array([0, 25, 50, 75, 100, 125, 150, 175, 200, 225, 250, 275, 300]) #time in minutes
CADATA = np.array([0.0481, 0.0452, 0.0386, 0.0330, 0.0321, 0.0273, 0.0253, 0.0243, 0.0231, 0.0201, 0.0196, 0.0188, 0.0170])
CATHIRD = np.sqrt(1/(1/CA0**2 + 2*k*tDATA))
RESID = CADATA - CATHIRD
SSE = np.sum(RESID**2)
return SSE
def JACTHREE(k):
CA0 = 0.05 #mol/L
tDATA = np.array([0, 25, 50, 75, 100, 125, 150, 175, 200, 225, 250, 275, 300]) #time in minutes
CADATA = np.array([0.0481, 0.0452, 0.0386, 0.0330, 0.0321, 0.0273, 0.0253, 0.0243, 0.0231, 0.0201, 0.0196, 0.0188, 0.0170])
JAC = (1/(1/CA0**2 + 2*k*tdata))**(-1/2) * -tdata/(1/CA0**2 + 2*k*tdata)**2
return JAC
ans3 = opt.minimize_scalar(OBJTHREE, method = 'Brent', bracket = [0.01, 0.05])
SSE3 = ans3.fun
k3 = ans3.x
#Calculate result for best fit first order model
tsmooth = np.linspace(0, max(tdata), 100)
CA0 = 0.05 #mol/L
CAPRED3 = np.sqrt(1/(1/CA0**2 + 2*k3*tdata))
CMOD3 = np.sqrt(1/(1/CA0**2 + 2*k3*tsmooth))
JAC3 = JACTHREE(k3)
Ndata = len(tdata)
DOF = Ndata - 1
MSE3 = SSE3/Ndata
RMSE3 = np.sqrt(MSE3)
MAE3 = 1/Ndata*np.sum(np.abs(CAdata - CAPRED3))
COV3 = SSE3/DOF*1/(JAC3.T@JAC3)
SEk3 = np.sqrt(COV3)
tval = stats.t.ppf(0.975, DOF)
CIk3 = tval*SEk3
CAbar = np.mean(CAdata)
SST3 = np.sum((CAdata - CAbar)**2)
R23 = 1 - SSE3/SST3
print('\n', ans3, '\n')
labels = ['k', 'α', 'SSE', 'MSE', 'RMSE', 'MAE', 'R2']
values = [k3, 3, SSE3, MSE3, RMSE3, MAE3, R23]
for label, value in zip(labels, values):
if label == 'k':
print(f'{label:4s} = {value:0.2E} +/- {CIk3:0.2E}')
else:
print(f'{label:4s} = {value:0.2E}')
#Overlay best fit model with data
plt.figure(1, figsize = (5, 5))
plt.scatter(tdata, CAdata, marker = 'o', color = 'none', edgecolor = 'black', label = 'CA')
plt.plot(tsmooth, CMOD3, color = 'black', linestyle = 'dashed')
plt.title('Third Order Nonlinear Regression')
plt.xlabel('time (min))', fontsize = 12)
plt.ylabel('CA (M))', fontsize = 12)
plt.xlim(0, max(tdata))
# plt.xticks(np.arange(-4.5, -2.49, 0.5))
# plt.minorticks_on()
plt.ylim(0, 0.06)
plt.show()
plt.figure(2, figsize = (5, 5))
plt.scatter(tdata, (CAdata - CAPRED3), marker = 'o', color = 'none', edgecolor = 'black', label = 'CA')
plt.hlines(0, 0, max(tdata), color = 'black', linestyle = 'dashed')
plt.title('Residual Plot for Third Order')
plt.xlabel('time (min))', fontsize = 12)
plt.ylabel('CA (M))', fontsize = 12)
plt.xlim(0, max(tdata))
# plt.xticks(np.arange(-4.5, -2.49, 0.5))
# plt.minorticks_on()
#plt.ylim(0, 0.06)
plt.show()
fun: 4.6162100913375796e-05
nfev: 22
nit: 9
success: True
x: 3.6669266010142807
k = 3.67E+00 +/- 5.10E-01
α = 3.00E+00
SSE = 4.62E-05
MSE = 3.55E-06
RMSE = 1.88E-03
MAE = 1.52E-03
R2 = 9.63E-01
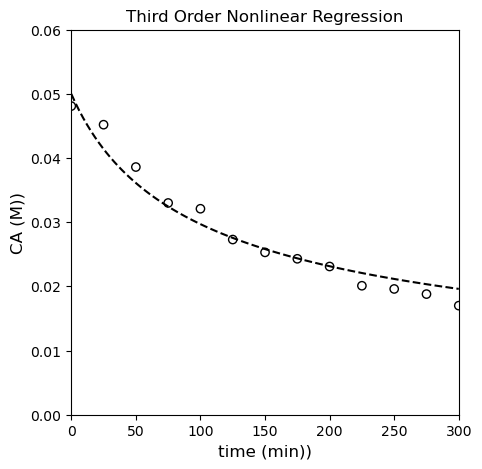
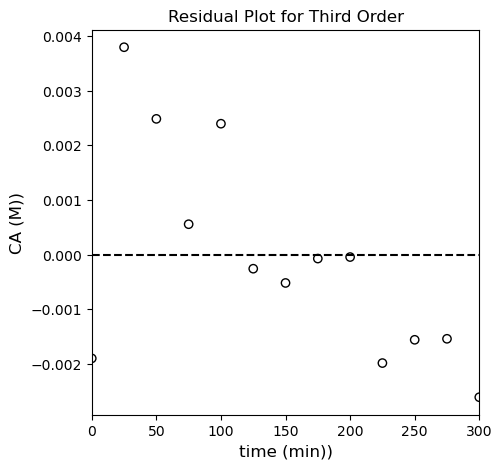
Alright…looks like we’ve gone a little too far. The third order model is slightly better than the first order model and slightly worse than the second order model. Any of them probably do an OK job of fitting the data, but quantitatively, the second order model is probably just a bit better.
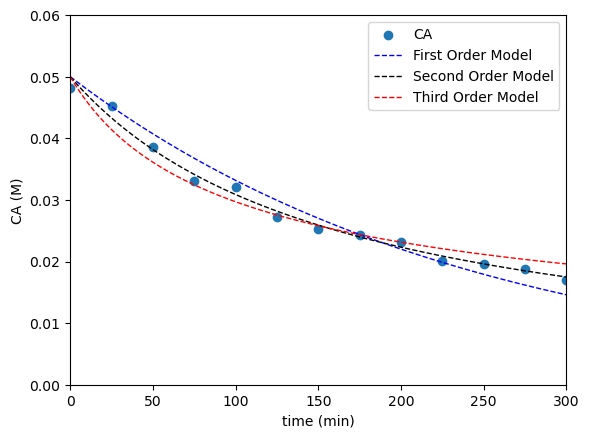
As we discussed during Lecture 29, it can be really hard to tell whether or not a model is “correct” just by visual inspection. All of the above, in isolation, seem to fit the data prett well. We’ll overlay all three where you can start to see that the second order model does the best. Then, we’ll look at linearized models if we can to see if we can see some deviation from linearity.
#Overlay best fit models with data
plt.scatter(tdata, CAdata, label = 'CA')
plt.plot(tsmooth, CMOD1, color = 'blue', linewidth = 1, linestyle = 'dashed', label = 'First Order Model')
plt.plot(tsmooth, CMOD2, color = 'black', linewidth = 1, linestyle = 'dashed', label = 'Second Order Model')
plt.plot(tsmooth, CMOD3, color = 'red', linewidth = 1, linestyle = 'dashed', label = 'Third Order Model')
plt.xlabel('time (min)')
plt.ylabel('CA (M)')
plt.ylim(0, 0.06)
plt.xlim(0, max(tdata))
plt.legend()
plt.show()
Linearization of Data#
First Order Linearization#
For the first order model, we have:
This is a nonlinear function of, essentially kt; however, if we take the natural logarithm of both sides, we convert it to the following, which is much more useful:
If we plot \(C_A\) against time, that should be linear if the first order model is correct. The slope would be equal to -k, and the y-intercept would be ln(CA0).
This is plotted in the cell below, where you observe linearity.
plt.figure(1, figsize = (5, 5))
plt.scatter(tdata, np.log(CAdata), marker = 'o', color = 'none', edgecolor = 'black', label = 'CA')
plt.title('First Order Linearization')
plt.xlabel('time (min)', fontsize = 12)
plt.ylabel('ln(CA (M))', fontsize = 12)
plt.xlim(0, max(tdata))
plt.show()
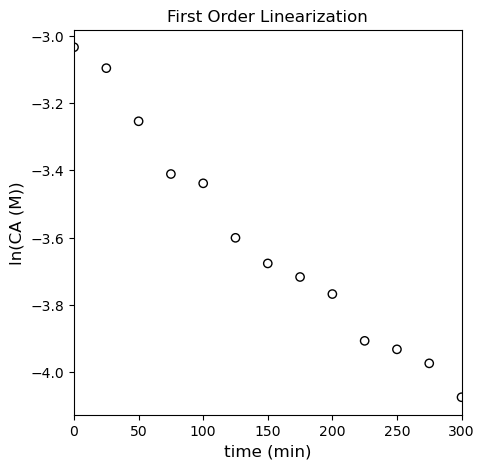
It looks pretty linear in isolation, but if we regress the line of best fit, we start to see systematic deviations; we’ll use np.polyfit() and also calculate all of the relevant meta statistical information. It’s a little more convenient here because you can automate some of the calculations, and it will also return things like the minimum SSE (this is enabled by switching the option full to True). I’ll use the SSE and SST to calculate the R2 for this fit. Note that SST is going to be based on \(\ln(CA)\) and the mean value of \(\ln(CA)\) for this linearized model.
ydata = np.log(CAdata)
A, SSE, rank, sing, rcond = np.polyfit(tdata, ydata, 1, full = True)
A, COV = np.polyfit(tdata, ydata, 1, full = False, cov = True)
ypred = np.polyval(A, tdata)
SSE = SSE[0]
k = -1*A[0]
CAs = np.exp(A[1])
Ndata = len(tdata)
MSE = SSE/Ndata
RMSE = np.sqrt(MSE)
MAE = 1/Ndata*np.sum(np.abs(ydata - ypred))
ybar = np.mean(ydata)
SST = np.sum((ydata - ybar)**2)
R2 = 1 - SSE/SST
DOF = len(ydata) - len(A)
SEm = np.sqrt(COV[0, 0])
SEb = np.sqrt(COV[1, 1])
tval = stats.t.ppf(0.975, DOF)
CIm = SEm*tval
CIb = SEb*tval
llb = A[1] - CIb
ulb = A[1] + CIb
Cll = np.exp(llb)
Cul = np.exp(ulb)
labels = ['k', 'CAs', 'SSE', 'MSE', 'RMSE', 'MAE', 'R2']
values = [k, CAs, SSE, MSE, RMSE, MAE, R2]
for label, value in zip(labels, values):
if label == 'k':
print(f'{label:4s} = {value:0.2E} +/- {CIm:0.2E}')
elif label == 'CAs':
print(f'{label:s} is between {Cll:0.2E} and {Cul:0.2E} with a regressed value of {value:0.2E}...')
else:
print(f'{label:4s} = {value:0.2f}')
plt.figure(1, figsize = (5, 5))
plt.scatter(tdata, ydata, marker = 's', color = 'none', edgecolor = 'black', label = 'CA')
plt.plot(tdata, np.polyval(A, tdata), color = 'black', linestyle = 'dashed')
plt.title('First Order Linearization')
plt.xlabel('time (min))', fontsize = 12)
plt.ylabel('ln (CA (M))', fontsize = 12)
plt.xlim(0, max(tdata))
plt.show()
plt.figure(2, figsize = (5, 5))
plt.scatter(tdata, (ydata - ypred), marker = 'o', color = 'none', edgecolor = 'black', label = 'CA')
plt.hlines(0, 0, max(tdata), color = 'black', linestyle = 'dashed')
plt.title('Residual Plot for First order')
plt.xlabel('time (min))', fontsize = 12)
plt.ylabel('Residual (M))', fontsize = 12)
plt.xlim(0, max(tdata))
plt.show()
k = 3.43E-03 +/- 3.63E-04
CAs is between 4.26E-02 and 4.84E-02 with a regressed value of 4.54E-02...
SSE = 0.03
MSE = 0.00
RMSE = 0.05
MAE = 0.04
R2 = 0.98
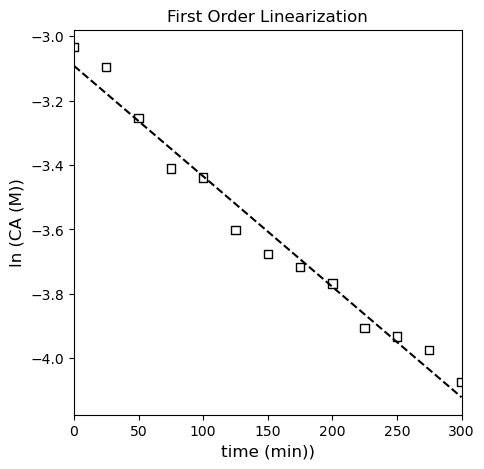
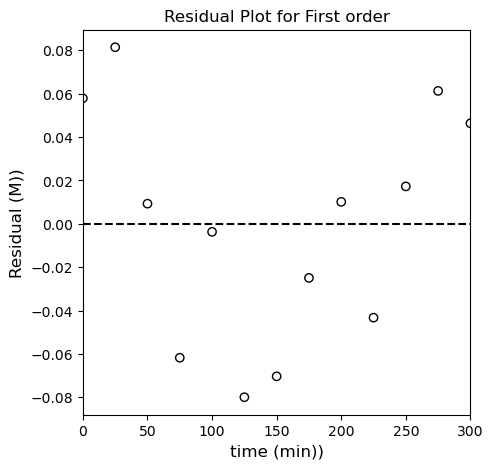
Second Order Model
For the second order model, we have:
We should see linearity here if we plot \(\frac{1}{C_A}\) vs \(t\). See below; this model clearly shows less deviation from linearity than the first order linearization.
plt.figure(1, figsize = (5, 5))
plt.scatter(tdata, 1/CAdata, marker = 'o', color = 'none', edgecolor = 'black', label = 'CA')
plt.title('second order linearization')
plt.xlabel('time (min)', fontsize = 12)
plt.ylabel('1/CA (M^-1)', fontsize = 12)
plt.xlim(0, max(tdata))
plt.show()
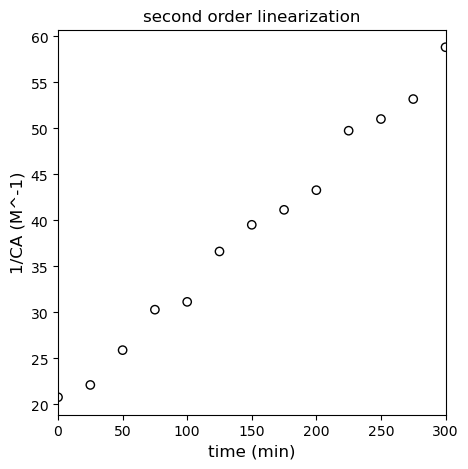
Below, I regress the coefficients for the linearized second order model using polyfit and overlay it with the “linearized” data set.
ydata = 1/CAdata
A, SSE, rank, sing, rcond = np.polyfit(tdata, ydata, 1, full = True)
A, COV = np.polyfit(tdata, ydata, 1, full = False, cov = True)
ypred = np.polyval(A, tdata)
SSE = SSE[0]
k = A[0]
k2 = A[0]
CAs = 1/A[1]
Ndata = len(tdata)
MSE = SSE/Ndata
RMSE = np.sqrt(MSE)
MAE = 1/Ndata*np.sum(np.abs(ydata - ypred))
ybar = np.mean(ydata)
SST = np.sum((ydata - ybar)**2)
R2 = 1 - SSE/SST
DOF = len(ydata) - len(A)
SEm = np.sqrt(COV[0, 0])
SEb = np.sqrt(COV[1, 1])
tval = stats.t.ppf(0.975, DOF)
CIm = SEm*tval
CIb = SEb*tval
llb = A[1] - CIb
ulb = A[1] + CIb
Cll = 1/llb
Cul = 1/ulb
labels = ['k', 'CAs', 'SSE', 'MSE', 'RMSE', 'MAE', 'R2']
values = [k, CAs, SSE, MSE, RMSE, MAE, R2]
for label, value in zip(labels, values):
if label == 'k':
print(f'{label:4s} = {value:0.2E} +/- {CIm:0.2E}')
elif label == 'CAs':
print(f'{label:s} is between {Cll:0.2E} and {Cul:0.2E} with a regressed value of {value:0.2E}...')
else:
print(f'{label:4s} = {value:0.2f}')
plt.figure(1, figsize = (5, 5))
plt.scatter(tdata, ydata, marker = 's', color = 'none', edgecolor = 'black', label = 'CA')
plt.plot(tdata, np.polyval(A, tdata), color = 'black', linestyle = 'dashed')
plt.title('Second Order Linearization')
plt.xlabel('time (min))', fontsize = 12)
plt.ylabel('ln (CA (M))', fontsize = 12)
plt.xlim(0, max(tdata))
plt.show()
plt.figure(2, figsize = (5, 5))
plt.scatter(tdata, (ydata - ypred), marker = 'o', color = 'none', edgecolor = 'black', label = 'CA')
plt.hlines(0, 0, max(tdata), color = 'black', linestyle = 'dashed')
plt.title('Residual Plot for Second order')
plt.xlabel('time (min))', fontsize = 12)
plt.ylabel('Residual (M))', fontsize = 12)
plt.xlim(0, max(tdata))
plt.show()
k = 1.26E-01 +/- 7.70E-03
CAs is between 5.39E-02 and 4.70E-02 with a regressed value of 5.02E-02...
SSE = 15.30
MSE = 1.18
RMSE = 1.08
MAE = 1.00
R2 = 0.99
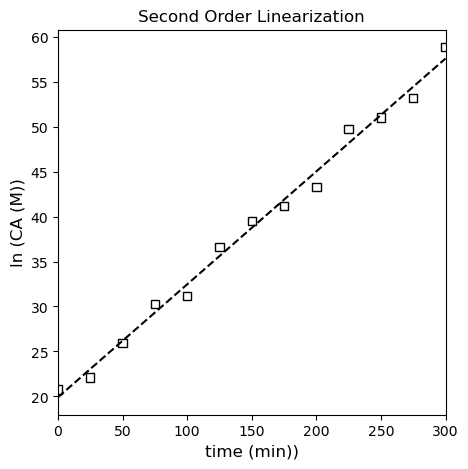
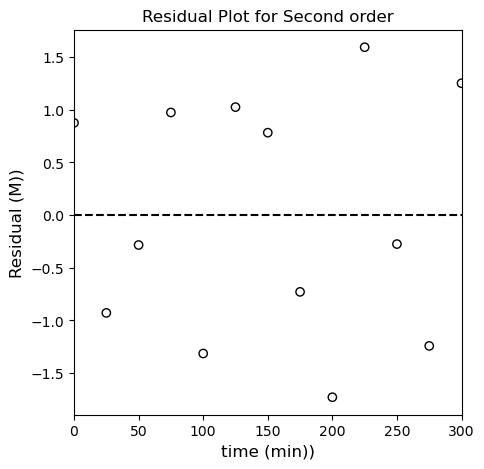
I like the second order fit! I can see scatter around the line of best fit instead of a systematic deviation like in the first order model. Let’s check the third order linearization just to see if the second order model still looks better.
For the third order model, we have a slightly different linearization that is based on this form of the integrated model:
If we plot \(\frac{1}{{C_A}^2}\) vs time, we should see linearity if the third order model is correct.
ydata = 1/CAdata**2
A, SSE, rank, sing, rcond = np.polyfit(tdata, ydata, 1, full = True)
A, COV = np.polyfit(tdata, ydata, 1, full = False, cov = True)
ypred = np.polyval(A, tdata)
SSE = SSE[0]
k = A[0]/2
CAs = np.sqrt(1/A[1])
Ndata = len(tdata)
MSE = SSE/Ndata
RMSE = np.sqrt(MSE)
MAE = 1/Ndata*np.sum(np.abs(ydata - ypred))
ybar = np.mean(ydata)
SST = np.sum((ydata - ybar)**2)
R2 = 1 - SSE/SST
DOF = len(ydata) - len(A)
SEm = np.sqrt(COV[0, 0])
SEb = np.sqrt(COV[1, 1])
tval = stats.t.ppf(0.975, DOF)
CIm = SEm*tval/2
CIb = SEb*tval
llb = A[1] - CIb
ulb = A[1] + CIb
Cll = np.sqrt(1/llb)
Cul = np.sqrt(1/ulb)
labels = ['k', 'CAs', 'SSE', 'MSE', 'RMSE', 'MAE', 'R2']
values = [k, CAs, SSE, MSE, RMSE, MAE, R2]
for label, value in zip(labels, values):
if label == 'k':
print(f'{label:4s} = {value:0.2E} +/- {CIm:0.2E}')
elif label == 'CAs':
print(f'{label:s} is between {Cll:0.2E} and {Cul:0.2E} with a regressed value of {value:0.2E}...')
else:
print(f'{label:4s} = {value:0.2f}')
plt.figure(1, figsize = (5, 5))
plt.scatter(tdata, ydata, marker = 's', color = 'none', edgecolor = 'black', label = 'CA')
plt.plot(tdata, np.polyval(A, tdata), color = 'black', linestyle = 'dashed')
plt.title('Third Order Linearization')
plt.xlabel('time (min))', fontsize = 12)
plt.ylabel('ln (CA (M))', fontsize = 12)
plt.xlim(0, max(tdata))
plt.show()
plt.figure(2, figsize = (5, 5))
plt.scatter(tdata, (ydata - ypred), marker = 'o', color = 'none', edgecolor = 'black', label = 'CA')
plt.hlines(0, 0, max(tdata), color = 'black', linestyle = 'dashed')
plt.title('Residual Plot for Third order')
plt.xlabel('time (min))', fontsize = 12)
plt.ylabel('Residual (M))', fontsize = 12)
plt.xlim(0, max(tdata))
plt.show()
k = 4.88E+00 +/- 5.84E-01
CAs is between NAN and 5.12E-02 with a regressed value of 7.55E-02...
SSE = 351988.52
MSE = 27076.04
RMSE = 164.55
MAE = 123.52
R2 = 0.97
C:\Users\jqbon\AppData\Local\Temp\ipykernel_4548\3405713205.py:24: RuntimeWarning: invalid value encountered in sqrt
Cll = np.sqrt(1/llb)
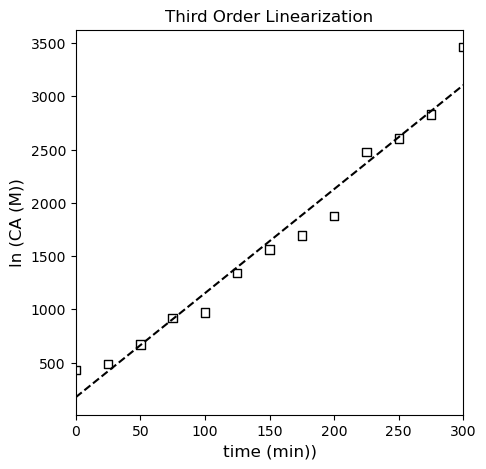
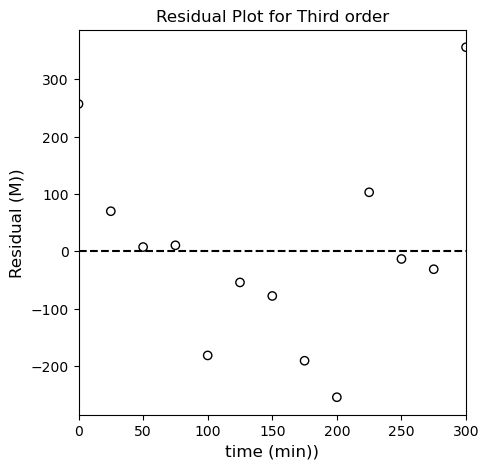
From everything we’ve done to this point, I am fairly confident in concluding that our reaction is second order in species A, so our rate law is:
Remember, way back when we started this problem, that we defined \(k^\prime\) as a lumped rate constant:
We know that the starting concentration of B in this system was 0.5M, so we can calculate the true rate constant as:
And our final rate law is:
print(f'Our most precise estimate of the lumped rate constant is {k2:3.3f} L/mol/min')
print(f'The true rate constant is {k2/0.5:3.3f} L^2 mol^-2 min^-1')
Our most precise estimate of the lumped rate constant is 0.126 L/mol/min
The true rate constant is 0.251 L^2 mol^-2 min^-1
If Time Allows, we can come back to this point#
Considering all of the analysis, the second order model seems to fit the data best. Since we know that the initial value of \(C_{A0}\) is 0.05M, we can improve our precision on the rate constant estimation slightly by choosing to not regress the y-intercept. We can do that by rearranging our linearization slightly:
Instead of working with:
And plotting \(\frac{1}{C_A}\) vs. time, we will work with this form:
And we will plot \(\frac{1}{C_A} - \frac{1}{C_{A0}}\) vs time. Alternatively, you could work with this form; either should give you a linear model with a zero y intercept:
I’ll use the first form to construct the matrix form of our linear least squares problem:
Where X is a vandermonde matrix created from tdata; however, we only keep the first order powers of time here (since there is no zero order coefficient in the model). Y, in this case, is \(\frac{1}{C_A} - \frac{1}{C_{A0}}\), and A is only a single coefficient, namely the slope of the line. See below for implementation. We can’t use polyfit here, but if we know how to work with the vandermonde matrix, we have a lot of flexibility in regressions. This is similar to what you can do with the LINEST function in Excel.
We’ll leave the discussion of calculating standard error and confidence intervals for another day (or maybe explore sklearn utilities a bit).
X = tdata.reshape(len(tdata),1) #I'm reshaping to make a 2D column instead of a 1D array; I have to do this to get dimensions correct for matrix product below
Y = 1/CAdata - 1/CA0
A = np.linalg.solve(X.T@X, X.T@Y)
plt.scatter(tdata, 1/CAdata - 1/CA0)
plt.plot(tsmooth, A*tsmooth, color = 'black', linestyle = 'dashed')
plt.title('second order linearization')
plt.xlabel('time (min)')
plt.ylabel('1/(CA)')
plt.xlim(0, 300)
plt.ylim(0, 40)
plt.show()
print(f'Our most precise estimate of the lumped rate constant is {A[0]:3.3f} inverse minutes')
print(f'The true rate constant is {A[0]/0.5:3.3f} M^-1 min^-1')
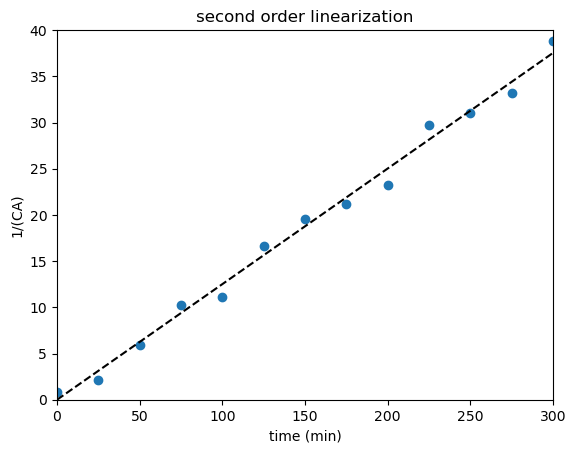
Our most precise estimate of the lumped rate constant is 0.125 inverse minutes
The true rate constant is 0.250 M^-1 min^-1